Dolmen is a generator of lexical analyzers and parsers for the Java programming language. It will produce lexical analyzers (resp. syntactic analyzers) based on textual lexer descriptions (resp. grammar descriptions). Dolmen can be used declaratively, as a library, to produce lexers and parsers from descriptions, or more commonly as a command-line tool. There also exists a dedicated Eclipse plug-in for Dolmen.
Introduction
In this section, we shortly introduce the notions of lexical and syntactic analyses and how they are typically combined into parsers for structured languages such as programming languages, configuration files, markup, etc. For a more thorough presentation of these concepts, one can for instance refer to resources such as [ASU] and [App]. If you are familiar with these concepts, you can skip directly to the documentation for Dolmen Lexical Analyzers or Parsers.
From characters to abstract syntax trees
To illustrate the kind of tasks that Dolmen may help you perform, consider a couple of statements in some programming language:
x = 1 + y * 3;
# Some comment
if (x < 0) then printf("(if;=\"#1\n");These statements are initially read from a source file as a mere sequence of characters. The process of turning this sequence of characters into a structured object that can be manipulated by a program (e.g. an interpreter, a compiler, a static analyzer, etc) is called parsing. For the statements above, the structured object would typically look somewhat like this:
Sequence
├─ Assignment
│ ├─ Variable "x"
│ └─ Add
│ ├─ Integer 0x00000001
│ └─ Mult
│ ├─ Variable "y"
│ └─ Integer 0x00000003
└─ IfThenElse
├─ LessThan
│ ├─ Variable "x"
│ └─ Integer 0x00000000
├─ Call "printf"
│ └─ String ['i' 'f' ';' '=' '"' '#' '1' 0x0A]
└─ Nop
Such a structure is usually called an Abstract Syntax Tree (AST), as it conveys the actual abstract structure that is expressed in the original syntactic piece of code. There are a few important things to note when comparing the AST and the original source:
-
Punctuation and operator symbols do not appear in the AST as such but they contribute to its structure:
-
punctuation symbols, such as semi-colons used to terminate statements, block delimiters or separation whitespace (e.g. the space between
thenandprintf), are useful to express the structure of the program and separate its core syntactic elements; they are reflected in the AST for instance in theSequencenode or theIfThenElsecontrol-flow structure; -
operators such as
+,if .. thenor=are translated to abstract nodes for the operations they represent, such asAssignment,Addand so on.It is technically possible to modify these syntactic conventions in the language and adapt the source snippet without changing the AST at all, i.e. without needing to change the back-ends of your compiler, interpreter, etc.
-
-
Comments do not appear in the AST as they have no bearing on the actual meaning of the program (the same goes for extra whitespace as well, e.g. indentation or formatting). Of course, a tool which needs to interpret some special comments (such as Javadoc or Doxygen documentation) will typically have to keep at least some of the comments as part of the AST.
-
Some things that were implicit in the original source have been made explicit in the AST:
-
rules that govern the precedence of various operators have been applied; in that case the fact that the multiplication operator
*binds tighter than the addition operator+is reflected in the way the arithmetic expression1 + y * 3was parsed; -
some forms of syntactic sugar have been removed, such as the missing
elsebranch being filled with a default no-operationNopnode.In essence, a program manipulating an AST need not care about all the subtle syntactic possibilites to write the same statement or expression, and writing
1 + (y * 3)or an explicitelse {}branch would have made no difference.
-
-
Last but not least, constant literals are also usually canonized in ASTs:
-
integer literals may be input using decimal, hexadecimal or octal notations for instance, and it is the actual value represented by the literal which is normally stored in the AST;
-
string or character literals may contain escape sequences for Unicode values or special characters such as
"and the line feed\nin our example, and these are replaced by the actual encoded character when parsing the literal into the AST.
-
Some of the things that are typically not performed during parsing
include the resolution of identifiers (is x a global constant or
some local variable? is printf a local function or one from an
imported external module?…), type-checking (calling printf(4, x)
would have been parsed successfully) and other semantic analyses.
Tokenization
Although it is always technically possible, it should be clear that manually parsing source code into an AST in a single-pass is not very practical: one needs to keep track of all possible contexts, handle possible comments everywhere, match opening and closing delimiters such as parentheses and braces, handle precedence rules and syntactic varieties, unescape characters when applicable, etc. It is code that is definitely hard to write, hard to read and even harder to maintain.
Tokens
A better way of handling this parsing problem is to first split the source code into its atomic lexical elements, much like reading a sentence in a natural language requires to first identify the various words before checking whether their arrangement is grammatically correct. These lexical elements are called tokens and the phase which transforms the input stream of characters into a stream of tokens is called tokenization.
The tokens of a programming language usually consist of:
-
punctuation symbols such as
;,,,(… -
operators such as
+,==,<<,&,>=… -
keywords of the language such as
if,while,def… -
identifiers such as
x,_y12,speedX… -
constant literals such as
12,0xFA2E,0.85f,'c',"hello"…
In particular, there are usually no tokens for whitespace or comments, although there could be tokens for special documentation comments if required. Looking at these couple of statements again:
x = 1 + y * 3;
# Some comment
if (x < 0) then printf("(if;=\"#1\n");the corresponding tokens would be
x, =, 1, +, y, *, 3, ;, if, (, x, <, 0, ),
then, printf, "(if;=\"#1\n", ) and ;.
Some tokens such as constant literals or identifiers are associated to a value, such as the literal’s value or the identifier’s name, whereas the other tokens hold no particular value other than themselves.
Regular Expressions
The tokenization process is usually simple enough for the different tokens to be recognizable by regular expressions. For instance, one might informally describe some of the rules to identify the tokens of our language above as follows:
";" -> SEMICOLON "&" -> AMPERSAND ... "if" -> IF "def" -> DEF ... [_a-zA-Z][_a-zA-Z0-9]* -> IDENT (0 | [1-9][0-9]*) -> INT ... '"' [^"] '"' -> STRING
where SEMICOLON, IF, IDENT, etc. are the symbolic names given to
the different kinds of tokens. The regular expressions for operators
and keywords are straightforward and match the associated symbols
exactly. Identifiers are simply a letter or an underscore followed by
any number of alphanumeric characters, whereas decimal integer
literals are either 0 or any number not starting with 0. There would
be other rules for integer literals in other radices, but they could
share the same token kind. Finally, string literals are formed by a
pair of matching " without any double quotes in the middle; of
course this is an oversimplification as it does not account for
escaped characters appearing inside the string. The different rules
are not necessarily exclusive, in which case some disambiguation
rules must be applied. For instance, keywords look very much like
valid identifiers, and in fact they are pretty much just that:
reserved identifiers. A common way of handling this is to use the
"longest-match rule", expressing that when a choice exists, the
token that consumes the most characters in the input should be given
preference. This ensures that defined is a single identifier token
instead of the keyword def followed by an identifier ined, and
that 1234 is a single integer instead of 1 followed by 234 or
any other combination. When several rules match the same amount of
input, a possible choice is to always pick the one which appears first
in the set of rules; in our case above, this ensures the keyword if
is matched as IF and not as an identifier.
Disambiguation aside, these regular expressions can be merged into a single regular expression which in turn can be transformed into a deterministic finite automaton (DFA) that recognizes the tokens. The final states of the DFA represent the various token rules and the DFA can be used to efficiently consume characters from the input stream. When the DFA reaches a final state, it emits the corresponding token, and in this fashion the input character stream can be transformed into a token stream. If ever the DFA fails to recognize the input characters at some point, this means the input string has a syntax error. With our rules above, this would for instance happen with an non-terminated string literal. Last but not least, we have not explained how whitespace and comments are handled: they must definitely be recognized and consumed but should produce no tokens. One way to do this in our informal description is to add the corresponding rules:
(' ' | '\r' | '\n' | '\t')+ -> /* whitespace, skip */
"//" [^\r\n]* -> /* comments, skip */
but have them produce no token at all. When the DFA reaches the corresponding state, it simply starts over with the remaining input without emitting any token in the output stream.
Lexical Analyzer Generators
Lexical analyzer generators are tools which automate the process of turning a set of rules, such as those given informally above, into source code which implements the recognition mechanism for the DFA associated with the rules. This allows developers to keep a reasonably abstract view of the tokenization process, concentrate on designing the various regular expressions correctly, and leave everything else to the generator:
-
managing the input stream buffer and character encoding;
-
the translation of the regular expressions into an optimized DFA;
-
handling disambiguation rules, in particular the backtracking which is normally entailed by using the longest-match rule;
-
checking for potential ambiguities or issues in the rules, such as rules which are always shadowed by another rule;
-
keeping track of line and column numbers or character offsets, which are useful both for error reporting and to associate source locations to AST nodes during the parsing phase.
As none of the above is particularly easy to deal with, these generators are a great asset when trying to write a parser. Many generators, including Dolmen, will additionnally support input rules which are more expressive than simple regular expressions, like pushdown automata, making it possible to perform quite complex tasks during the tokenization phase.
Some lexical analyzer generators such as the ones in ANTLR or JavaCC are intrinsically linked to an associated parser generator and are used to produce tokens for these parsers, but lexical analysis is not limited to producing tokens for a grammar-based syntactic analysis. One can actually associate the lexer rules to any computable action, such as printing something or aggregating some information. Possible applications of a "standalone" lexical analyzer may be:
-
counting the lines or the number of occurrences of some lexical element in a file, skipping comments;
-
perform simple C-style pre-processing of a program;
-
simple syntax highlighting such as the one applied to code blocks in this very document;
-
character stream transformation passes such as the initial Unicode unescaping phase in lexical translation of Java sources.
Lexers generated by Dolmen are not specialized for tokenization and can be used for any kind of lexical analysis by designing the appropriate actions. Another lexer generator in the Java ecosystem which produces standalone lexical analyzers is JFlex. In particular both can be used to produce token streams for other parser generators such as Cup or BYacc/J. The Lexical Analyzers chapter in this documentation explains how to write your own lexers with Dolmen.
Parsing
Coming soon
Lexical Analyzers
In this chapter, we explain how to produce lexical analysers with Dolmen by writing Dolmen lexer descriptions. We start by showing how to write a simple lexer description for the JSON format before presenting the various features of the lexer description format in more detailed fashion. A complete reference for the lexer description syntax can be found at the end of this chapter.
A Complete Example: Lexical Analyzer for JSON
We introduce lexical analysis with Dolmen by writing a lexical analyzer for the JavaScript Object Notation (JSON) format. JSON is a very common format for data exchange which has generally less overhead than XML and is more human-readable. A possible JSON value can be as follows:
{ "persons": ["Joe", "Bob", null],
"open": true,
"loc": [-12.45, 3.40e1],
"text": "sdfk\"j"
}A JSON value can be an object mapping string keys to other JSON
values, an array of values, a string, a number, or any of the three
literals true, false and null. In order to design a lexical
analyzer for this language, we need to recognize the following tokens:
-
the various punctuation symbols used in JSON:
{,},[,],:and,(note that",-,+and.are not considered as punctuation tokens, rather they are part of string and number literals); -
the keywords
true,falseandnull; -
the number literals such as
0,-1.34or0.699e+4; -
the string literals such as
"foo","\u0025\n"or"א".
Our lexical analyzer will need to recognize these various lexical elements and take actions upon doing so. A typical action when some token has been recognized is to build an object describing the token and return it; we will follow this principle here in this example but other actions such as printing the tokens could be possible.
In the following, we suppose we have some Java class mypackage.Token
describing the various tokens and some static factories to build
each kind of token:
| Token(s) | Static factory |
|---|---|
|
|
|
|
|
|
|
|
|
|
number |
|
string |
|
When writing a lexical analyzer to use wih a Dolmen-generated
parser, this Token class would simply be generated by Dolmen
from the token declarations in the grammar
description.
|
Dolmen Lexer Structure
The overall structure of a Dolmen lexer description is as follows:
... Options ...
... Java imports ...
{ ... /* Java prelude */ ... }
... Regexp definitions ...
... Lexer entries ...
{ ... /* Java postlude */ ... }We will come back to the options and regular expression definitions
parts later. The Java imports section contains plain
Java
import declarations which are added by Dolmen to the generated
lexical analyzer and can be used in the various Java actions of the
lexer description. In our case, we will import the Token class for
sure, and we may even import its static members to simplify access to
the token static factories:
import mypackage.Token;
import static mypackage.Token.*;The Java prelude and postlude are arbitrary Java snippets which will be added respectively to the top and bottom of the generated lexical analyzer. They can typically be used for local auxiliary methods or static initializers. We can leave them empty for now, and will come back and add convenient methods to the prelude if need arises.
The main part of a Dolmen lexer consists of lexer entries, of which there must be at least one per lexer. At this point, our partial lexer description looks like this and is just missing some entries:
import mypackage.Token;
import static mypackage.Token.*;
{ }
// TODO here: add some lexer entries!
{ }Adding Lexer Entries
When a lexical analyzer starts consuming a file, a string or any stream of characters, it needs a set of rules explaining what patterns must be recognized and what actions must be taken in response. In Dolmen lexer descriptions, such a set of rules is called a lexer entry and has the following structure:
visibility { ... /* return type */ ... } rule name =
| regexp { ... /* semantic action */ ... }
...
| regexp { ... /* semantic action */ ... }An entry has a visibility and a name; the entry’s visibility can be
either public or private and specifies the visibility of the
corresponding entry point in the generated lexer. Each of the
following line is called a clause and specifies some regular
expression and an associated semantic action in Java. Each entry
must have at least one clause.
Using a lexer entry will match the character stream for the regular expressions in the entry’s clauses, and when a match is found, will consume the corresponding part of the character stream and execute the corresponding Java action.
|
When more than one clause matches the input stream, disambiguation happens based on the two following rules:
|
The entry defines a Java return type which is the actual return type
of the corresponding Java entry point in the lexical analyzer, and the
semantic actions in the entry’s clauses must be consistent with that
return type. In the case of our JSON lexical analyzer, let us add a
main public rule which will return an instance of the Token class:
public { Token } rule main =
| ...We can first add the clauses to recognize the punctuation tokens, these clauses simply match the punctuation character and return the associated token:
...
| '{' { return LBRACE; }
| '}' { return RBRACE; }
| '[' { return LBRACKET; }
| ']' { return RBRACKET; }
| ':' { return COLON; }
| ',' { return COMMA; }When used in a regular expression, a simple character literal will
exactly match said character. Similarly, a double-quoted string literal
will exactly match the given string, so we can easily add clauses to
match the tokens for the true, false and null JSON keywords:
...
| "true" { return TRUE; }
| "false" { return FALSE; }
| "null" { return NULL; }The exact syntax for number literals is for instance described in the JSON standard by the following railroad diagram:
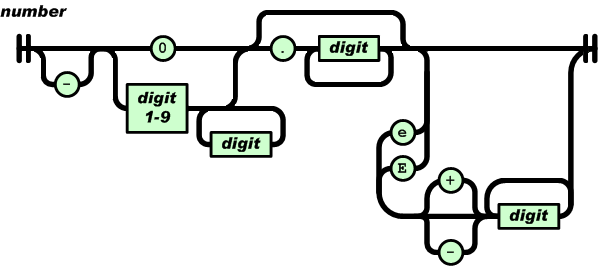
A JSON number literal is therefore a decimal integer (without leading zeroes), preceded by an optional sign, and optionally followed by a fractional part and/or an exponent part, allowing common scientific notation to be used. It is straightforward to translate that diagram into a regular expression, but that expression would get quite large, which is both error-prone and hard to maintain. To alleviate this issue, Dolmen allows defining auxiliary regular expressions and composing them into bigger regular expressions. In a lexer description, definitions of auxiliary regular expressions can be inserted between the prelude and the lexer entries. Let us add a few auxiliary definitions to our description in order to tackle number literals:
digit = ['0'-'9'];
nzdigit = digit # '0';
int = '-'? ('0' | nzdigit digit*);
...We define a digit as being any character between 0 and 9. The
[…] syntax defines a character set; it can contain any number of
single characters, as well as character ranges described by the first
and last characters of the range separated by -. The second
definition uses the difference operator # to define a non-zero
digit (nzdigit) as being any digit except 0. The difference
operator can only be used with characters or character sets and will
match any character in the left-hand side operand that is not also in
the right-hand operand. The third definition makes use of traditional
regular expression operators to define the integral part of a JSON
number literal: ? for an optional match, | for the choice operator
and * for matching any number of repetitions of a regular
expression. Of course, the operator + is not needed here but can
also be used to match one or more repetitions.
...
frac = '.' digit+;
e = ('e' | 'E') ('+' | '-')?;
exp = e digit+;
number = int frac? exp?;Similarly, it is straightforward to add definitions for the fractional
and exponent parts, and finally to define number as the concatenation
of the integral and (optional) fractional and exponent parts. We can
now simply use number in the clause which must match number literals
in the main lexer entry:
...
| number { return NUMBER(...); }Unlike the symbols and keywords we had matched so far, the number
token which must be constructed depends on the actual contents that
have been matched by the clause; in other words, we need to construct
the adequate double value to pass to the NUMBER static factory.
The string which has been matched can be retrieved in the semantic
action using the method getLexeme(). The various methods and fields
which are available in semantic actions to interact with the lexing
engine are listed in the reference section on
semantic actions. In our case here, we
can simply use getLexeme() and the
Double.parseDouble
method from the Java API:
...
| number { return NUMBER(Double.parseDouble(getLexeme())); }
You may note that not all strings matched by the number
regular expression are representations of valid Java
double-precision numbers (e.g. it can match arbitrary large
numbers), and that this semantic action could therefore throw a
NumberFormatException. We
will see later in this tutorial how to improve error reporting in
our lexer.
|
Compiling and Testing the Lexer
At this point, our lexer is far from finished but it is not too early to try and generate the lexical analyzer. As with regular programs, it is not advised to write several hundred lines of lexer description without stopping regularly to test their behaviour.
| In this tutorial, we will generate and test the lexical analyzer using a command line interface, which may seem a tad tedious. A more convenient way of using Dolmen is via the companion Eclipse plug-in. Nonetheless, the command line is useful in a variety of scenarios like building scripts, Makefile, continuous integration, etc. |
The best way to enjoy this tutorial is to try and proceed
along on your own system, following the different steps to
reach an actual complete JSON lexer. We provide an
archive
to set up a working directory just like the one we assume
in this section. This archive also contains a basic Makefile
to compile the lexer and tokenizer, and a target test which
runs the tokenizer as described below.
|
Suppose we have created a file JsonLexer.jl with our lexer
description so far, which looks as follows:
import mypackage.Token;
import static mypackage.Token.*;
{ }
digit = ['0'-'9'];
nzdigit = digit # '0';
int = '-'? ('0' | nzdigit digit*);
frac = '.' digit+;
e = ('e' | 'E') ('+' | '-')?;
exp = e digit+;
number = int frac? exp?;
public { Token } rule main =
| '{' { return LBRACE; }
| '}' { return RBRACE; }
| '[' { return LBRACKET; }
| ']' { return RBRACKET; }
| ':' { return COLON; }
| ',' { return COMMA; }
| "true" { return TRUE; }
| "false" { return FALSE; }
| "null" { return NULL; }
| number { return NUMBER(Double.parseDouble(getLexeme())); }
{ }We also assume our working directory has the following structure:
./
├─ Dolmen_1.0.0.jar
├─ bin/
│ └─ mypackage
│ └─ Token.class
└─ mypackage/
├─ Token.java
└─ JsonLexer.jl
Besides the source folder with our Token class and lexer file,
we also have a bin/ folder for compiled classes, where Token
has already been compiled, and the Dolmen JAR. The JAR contains
both the runtime for Dolmen-generated analyzers, and the command
line interface to Dolmen. We can invoke the latter to generate
a lexical analyzer from our JsonLexer.jl:
$ java -jar Dolmen_1.0.0.jar -o mypackage -p mypackage mypackage/JsonLexer.jl
Compiling lexer description mypackage/JsonLexer.jl
├─ Lexer description successfully parsed [77ms]
├─ Compiled lexer description to automata [57ms]
│ (29 states in 1 automata)
│ (1 potential problem found)
├─ Generated lexer in mypackage/JsonLexer.java [29ms]
└─ Done in 163msDolmen reports the various steps of the generation process and
successfully generates a Java compilation unit JSonLexer.java in the
mypackage directory (as instructed by the -o option). It also
found one "potential problem" along the way; unlike errors which are
fatal, problems are mere warnings which do not prevent the
generation of the analyzer. We will see below how to check and address
these problem reports, but for now let us continue with our main goal
and compile the generated analyzer:
$ javac -d bin -classpath bin:Dolmen_1.0.0.jar mypackage/JsonLexer.java
$ javap -public bin/mypackage/JsonLexer.class
Compiled from "JsonLexer.java"
public final class mypackage.JsonLexer extends org.stekikun.dolmen.codegen.LexBuffer {
public mypackage.JsonLexer(java.lang.String, java.io.Reader);
public mypackage.Token main();
}We have to add Dolmen_1.0.0.jar to the class path when invoking
javac since the JAR contains the Dolmen runtime that is used by the
generated lexer. Once the class is compiled, we can use the javap
disassembler tool to check that the generated lexer consists in a
single class JsonLexer with:
-
a public constructor taking a
java.io.Readeras an input character stream (the firstStringargument is a user-friendly source name and is only used in locations and error reports); -
a public method
mainreturning aToken, corresponding to our main lexer entry.
In order to actually test this generated lexer, we write the following
Tokenizer class in mypackage:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26 package mypackage;
import java.io.StringReader;
import org.stekikun.dolmen.common.Prompt;
import org.stekikun.dolmen.codegen.LexBuffer;
import mypackage.Token;
import mypackage.JsonLexer;
public class Tokenizer {
public static void main(String args[]) {
while (true) {
String line = Prompt.getInputLine(""); (1)
if (line == null || "".equals(line)) break;
JsonLexer lexer = new JsonLexer("stdin", new StringReader(line)); (2)
try {
while (true) {
System.out.println(lexer.main()); (3)
}
}
catch (LexBuffer.LexicalError e) { (4)
e.printStackTrace();
}
}
}
}
| 1 | Prompt.getInputLine
is provided for quick testing by
the Dolmen runtime and simply returns a line of standard
input. |
| 2 | We initialize a lexical analyzer with a stream formed of the single line of input text. |
| 3 | We call lexer.main() repeatedly to tokenize the input
stream and print the tokens. |
| 4 | lexer.main() will throw a LexicalError
exception when encountering unsuitable input. |
We can compile Tokenizer and execute it, this shows us
a prompt waiting for some input to feed to the lexical analyzer:
$ javac -d bin -classpath bin:Dolmen_1.0.0.jar mypackage/Tokenizer.java
$ java -classpath bin:Dolmen_1.0.0.jar mypackage.Tokenizer
>If we try a couple of very simple sentences using some JSON literals, we see the tokens seem to be recognized correctly but our lexer always ends up throwing an exception:
> true
TRUE
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Empty token (in stdin, at line 1, column 5)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:639)
at mypackage.JsonLexer.main(JsonLexer.java:67)
at mypackage.Tokenizer.main(Tokenizer.java:18)
> 3.14159e+0
NUMBER(3,14159)
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Empty token (in stdin, at line 1, column 11)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:639)
at mypackage.JsonLexer.main(JsonLexer.java:67)
at mypackage.Tokenizer.main(Tokenizer.java:18)
> {}
LBRACE
RBRACE
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Empty token (in stdin, at line 1, column 3)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:639)
at mypackage.JsonLexer.main(JsonLexer.java:67)
at mypackage.Tokenizer.main(Tokenizer.java:18)The Empty token lexical error is Dolmen’s way of expressing that the
input stream at this point did not match any of the clauses in the
main lexer entry. Dolmen also reports the position in the input stream
at which the error occurred, in our case it always seems to occur at
the end of our input string. Indeed, we never put any rule in our
lexer entry to express what needed to be done when running out of
input; because the entry cannot match an empty string either, it fails
with an empty token error when reaching end of input.
A typical way of handling the end of input when parsing a language is
to use a dedicated token to represent when it has been reached. In
order to produce such token, we need to write a clause which
recognizes the end of input specifically: for that purpose, the eof
keyword can be used in regular expressions inside Dolmen lexer
descriptions. eof will match the input if and only if the end of
input has been reached, and will not consume any of it. Therefore,
let us add a new token Token.EOF to our token factory, and
a new clause to our lexer description:
...
| eof { return EOF; }We also fix the inner loop of the Tokenizer class so that
it stops the lexical analysis as soon as it reaches the
EOF token:
...
Token tok;
while ((tok = lexer.main()) != Token.EOF) {
System.out.println(tok);
}
...After generating the lexer anew and recompiling everything, we see the end of input seems to be handled correctly now:
> false
FALSE
> 27.1828E-1
NUMBER(2,71828)
> [:]
LBRACKET
COLON
RBRACKETArmed with such success, surely we can start testing more complex sequences of tokens!
> [12.34e5, {false}, null]
LBRACKET
NUMBER(1,23400e+06)
COMMA
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Empty token (in stdin, at line 1, column 10)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:639)
at mypackage.JsonLexer1.main(JsonLexer1.java:70)
at mypackage.Tokenizer1.main(Tokenizer1.java:18)This time, the empty token error occurs at the space following the first comma in our input string. So far our clauses have only dealt with recognizing and producing actual tokens of the language, but we have not yet instructed the lexer as to what sequences of characters, if any, can safely be skipped during lexical analysis, in other words we have not dealt with whitespace. The JSON standard defines exactly what constitutes whitespace in a JSON file:
Insignificant whitespace is allowed before or after any token. Whitespace is any sequence of one or more of the following code points: character tabulation (U+0009), line feed (U+000A), carriage return (U+000D), and space (U+0020).Whitespace is not allowed within any token, except that space is allowed in strings.
We can now define a regular expression to match that definition and use it in a clause to correctly skip whitespace:
ws = ['\u0009' '\u000A' '\u000D' '\u0020']+;We will, for reasons that will be explained later on, do things slightly differently and handle regular whitespace and line terminators separately. Moreover, we use the more traditional escape characters to keep things more readable:
ws = ['\t' ' ']+;
nl = ('\n' | '\r' | "\r\n");
... // other regexps
public { Token } rule main =
| ws { continue main; }
| nl { continue main; }
... // other clausesAlong with the regular expressions, We added clauses at the beginning
of our main lexer entry to handle both whitespace and newline
sequences. The way we express in our semantic actions that the matched
whitespace should be skipped is by simply starting the main entry
again on the remaining input. There are mostly two ways to do that:
-
using a Java
continuestatement as we do here, to restart the current lexer entry without actually calling the Java method implementing the entry; this works because Dolmen always generates the code of a lexer entry in a loop with a labeled statement whose label is exactly the name of the entry; -
simply calling the
mainrule (tail-)recursively by writing{ return main(); }, which would have been almost equivalent to thecontinuealternative.
The trade-offs of choosing the latter over the continue statement
are discussed in advanced concepts, but
a good rule of thumb is that continue should be preferred whenever
possible.
After recompiling everything, we can test that whitespace now seems to be handled correctly, and we can tokenize non-trivial JSON contents:
> [false, 2.71828, [null, []], true]
LBRACKET
FALSE
COMMA
NUMBER(2,71828)
COMMA
LBRACKET
NULL
COMMA
LBRACKET
RBRACKET
RBRACKET
COMMA
TRUE
RBRACKETThe only JSON feature missing at this point in our lexer is actually string literals, and we will see how to handle them in the next section.
|
The JSON language does not allow comments, but this is where
comments would be handled in our lexical analyzer if we needed to.
Indeed, from a lexical point of view, comments are just delimited
parts of the input which serve as whitespace and separate the
actual tokens. For instance, a typical |
|
Note that the JSON standard does not make whitespace mandatory
between lexical elements. In particular, it is fine, even if perhaps
surprising at first, that our lexer analyzes the input string
This is the correct lexical analysis of the input, and stems from the fact that there are no lexical elements like user-defined "identifiers" in JSON. In a language with alphanumeric identifiers, the longest-match rule would ensure that this input be seen as the single identifier truefalse. Now, there is no valid JSON file where the keywords |
Adding More Entries
The last kind of tokens we need to recognize is string literals. Again, the JSON standard proposes a railroad diagram for JSON string values:

A literal string is therefore a sequence of unicode code points
delimited by double-quote characters. Between the delimiters, all
unicode code points are valid except for the control characters
(code points below 0x20), the backslash character \ and the
quotation mark " itself of course. The " and \ characters can be
inserted via escape sequences instead, as well as a few common
control characters. Finally, any code point in the Basic Multilingual
Plane can be inserted via its four-digit hexadecimal value using the
\uxxxx escaping sequence.
|
The JSON standard does not assume a particular encoding and
specifies characters using their Unicode code points. The whole point
of having In our case, Dolmen relies on Java and thus uses UTF-16, as does the
input stream in our |
A possible approach to recognizing these string literals would be to write a complex regular expression such as this:
hexDigit = ['0'-'9' 'a'-'f' 'A'-'F'];
escapeChar = ['"' '\\' '/' 'b' 'n' 'r' 'f' 't'];
escapeSeq = '\\' ( 'u' hexDigit<4> | escapeChar );
string = '"' ([^'\000'-'\037' '"' '\\'] | escapeSeq)* '"';and add the corresponding clause in our main lexer entry:
...
| string { return STRING(decode(getLexeme())); }where decode would be some Java method to decode the contents of the
literal string, by removing the quotation marks and replacing the
escape sequences with the characters they stand for. Now there are at
least two shortcomings with proceeding in this fashion:
-
the
decodemethod will have to match the contents of the string, including the various escape sequences, and that is exactly the job the lexer did whilst matching thestringregular expression; we are using a lexical analyzer generator precisely to avoid having to write such code manually so it would be quite disappointing to have to duplicate the analysis in this way; -
when a lexical error occurs inside a string literal, the input will not match the
stringregular expression and a lexical error will be raised at the position of the opening quotation mark; if the error is about an invalid character or an invalid escape sequence, it would be much more user-friendly and informative to actually report the error at its actual position, allowing a more specific error message and also showing that the contents of the string up to that point were valid.
The solution to both of those issues is simply to use the lexical
analyzer itself to recognize, and decode at the same time, the
contents of a string literal. As explained earlier in this tutorial, a
lexical analyzer can be used for many things besides simply tokenizing
input in a parser, and unescaping a string is one of them. To that
end, we introduce in JSonLexer.jl a new lexer entry called string:
private { String } rule string{StringBuilder buf} =
| '"' { return buf.toString(); }
...which differs from the main entry in several aspects:
-
The rule
stringhasprivatevisibility, which means the corresponding method will be a private Java method. Indeed,stringis intended to be called frommainand not from client code outside the analyzer. A Dolmen lexer description can have more than one public entry nonetheless. -
The return type for this rule is
Stringand notToken. Indeed, the purpose of this entry is to recognize and decode a string literal, and the result of a successful match will be the contents of the decoded literal. -
The rule
stringhas arguments, namely a single argumentbufwith typejava.lang.Stringbuilder. In Dolmen, lexer entries can be parameterized with arguments, which can be passed from client Java code or when calling an entry from another entry’s semantic action. In this case, the rule expects a buffer which will be filled as the contents of the string literal are matched.
This entry is intended to be called after encountering the opening
quotation mark of a string literal, and must stop at the corresponding
closing delimiter. This is handled by the first clause above, which
returns the contents of the given buffer buf when matching ". We
need two other clauses: one for escape sequences introduced by the \
character and the other for all other valid Unicode characters. Here
is our string entry in full:
private { String } rule string{StringBuilder buf} =
| '"' { return buf.toString(); }
| '\\' { char c = escapeSequence();
buf.append(c);
continue string;
}
| [^'\000'-'\037' '"' '\\']+
{ buf.append(getLexeme());
continue string;
}The third clause matches all non-escaped contents and uses the
[^…] construct to match all characters that do not belong to the
specified character set; the characters \000 and \037 are given in
octal code syntax and their interval corresponds to control
characters. Matched input in this clause is simply appended to the
string buffer that will be returned eventually, and the rule is
started over using the continue operator. Now the second clause is
more interesting as it deals with escape sequences; it simply matches
a backslash character and then calls a method escapeSequence to
retrieve the escaped character, append it to the buffer and continue
the analysis. This escapeSequence method is simply yet another lexer
entry whose job it is to parse and interpret any escape character or
code and return the corresponding character:
private { char } rule escapeSequence =
| 'b' { return '\b'; }
| 't' { return '\t'; }
| 'n' { return '\n'; }
| 'f' { return '\f'; }
| 'r' { return '\r'; }
| '"' { return '"'; }
| '\'' { return '\''; }
| '\\' { return '\\'; }
| '/' { return '/'; }
| 'u' (hexDigit<4> as code)
{ return ((char)(Integer.parseInt(code, 16))); }The rule escapeSequence is private, expects no arguments, and simply
returns a simple Java char. It matches all accepted escape
characters as well as Unicode escape codes. For the latter, the
regular expression hexDigit<4> as code is particularly interesting:
-
the repetition operator
r<n>is used to parse exactlynrepetitions of the regular expressionr; in its more general formr<n, m>, it matches fromnto (inclusive)mrepetitions ofr; -
the
asoperator is used to capture a sub-part of the input which matches a rule:r as idwill make the part of the input which matched the regular expressionravailable in the semantic action as a Java variable with the nameid; this avoids potentially costly manipulation of the lexeme string in the semantic action (in this case, extracting a suffix) which often duplicates some of the work that has been performed when matching the input in the first place.
For an example of how the as operator can really help improve
a clause, consider the Unicode
escape sequences in Java which accept any number of leading us,
using:
| 'u'+ (hexDigit<4> as code)
{ ... /* use code */ ... }is more readable and more efficient than a solution without captures:
| 'u'+ hexDigit<4>
{ String lex = getLexeme();
String code = lex.substring(lex.lastOf('u') + 1);
... /* use code */ ... }At this point, our string entry—and its auxiliary rule for escape
sequences—can recognize and decode JSon string literals' contents in
an elegant fashion, the last step is simply to call string from our
main lexer entry:
...
| '"' { return STRING(string(new StringBuilder())); }
...This simply matches the opening quotation mark, and calls the string
rule recursively with a fresh StringBuilder instance before
returning the overall token. Now, our analyzer’s entries are not
reentrant (or rather, they do not need to be), so it seems a bit
wasteful to build a StringBuilder instance for every string that we
are going to encounter, especially because typical JSON objects
contain many string literals, in part as keys of JSON objects. A more
resourceful way of proceeding is to use a single local buffer.
We can add such a buffer to the fields of the generated lexer by using
the prelude or postlude, which we had left empty so far, and adapt our
clause accordingly:
// Prelude
{
private final StringBuilder buffer = new StringBuilder(); (1)
}
// In the main entry
...
| '"' { buffer.setLength(0); (2)
String s = string(buffer);
return STRING(s);
}
...| 1 | Declare and initialize a local string buffer |
| 2 | Take care of clearing the buffer before passing it to the string rule. |
We are now ready to regenerate our lexical analyzer:
java -jar Dolmen_1.0.0.jar -o mypackage -p mypackage mypackage/JsonLexer.jl
Compiling lexer description mypackage/JsonLexer.jl
├─ Lexer description successfully parsed [83ms]
├─ Compiled lexer description to automata [66ms]
│ (51 states in 3 automata)
│ (3 potential problems found)
├─ Generated lexer in mypackage/JsonLexer.java [38ms]
└─ Done in 187msand after recompiling the Java units, we can finally handle full JSON:
> { "\u0025foo\\": [-1.34, "Foo", [null, "Barא", "\uD834\uDD1E"]] }
LBRACE
STRING(%foo\)
COLON
LBRACKET
NUMBER(-1,34000)
COMMA
STRING(Foo)
COMMA
LBRACKET
NULL
COMMA
STRING(Barא)
COMMA
STRING(𝄞)
RBRACKET
RBRACKET
RBRACEOur full lexer description now looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63 import mypackage.Token;
import static mypackage.Token.*;
{
private final StringBuilder buffer = new StringBuilder();
}
ws = ['\t' ' ']+;
nl = ('\n' | '\r' | "\r\n");
digit = ['0'-'9'];
nzdigit = digit # '0';
int = '-'? ('0' | nzdigit digit*);
frac = '.' digit+;
e = ('e' | 'E') ('+' | '-')?;
exp = e digit+;
number = int frac? exp?;
hexDigit = digit | ['a'-'f' 'A'-'F'];
public { Token } rule main =
| ws { continue main; }
| nl { continue main; }
| '{' { return LBRACE; }
| '}' { return RBRACE; }
| '[' { return LBRACKET; }
| ']' { return RBRACKET; }
| ':' { return COLON; }
| ',' { return COMMA; }
| "true" { return TRUE; }
| "false" { return FALSE; }
| "null" { return NULL; }
| number { return NUMBER(Double.parseDouble(getLexeme())); }
| '"' { buffer.setLength(0);
String s = string(buffer);
return STRING(s);
}
| eof { return EOF; }
private { String } rule string{StringBuilder buf} =
| '"' { return buf.toString(); }
| '\\' { char c = escapeSequence();
buf.append(c);
continue string;
}
| [^'\000'-'\037' '"' '\\']+
{ buf.append(getLexeme());
continue string;
}
private { char } rule escapeSequence =
| 'b' { return '\b'; }
| 't' { return '\t'; }
| 'n' { return '\n'; }
| 'f' { return '\f'; }
| 'r' { return '\r'; }
| '"' { return '"'; }
| '\'' { return '\''; }
| '\\' { return '\\'; }
| '/' { return '/'; }
| 'u' (hexDigit<4> as code)
{ return ((char)(Integer.parseInt(code, 16))); }
{ }
The description is merely 63 lines long, relatively easy to read and understand, and it can correctly analyze any correct JSON file! In the next section of this tutorial, we will see how to improve the lexer’s behaviour in the case where it is fed syntactically incorrect files.
Improving Error Reports
So far, we have designed a working lexical analyzer for JSON files, but we have kept ignoring the "potential problems" that are reported by Dolmen every time we regenerate the lexer from the description:
java -jar Dolmen_1.0.0.jar -o mypackage -p mypackage mypackage/JsonLexer.jl
Compiling lexer description mypackage/JsonLexer.jl
├─ Lexer description successfully parsed [94ms]
├─ Compiled lexer description to automata [79ms]
│ (52 states in 3 automata)
│ (3 potential problems found)
├─ Generated lexer in mypackage/JsonLexer.java [37ms]
└─ Done in 211msAs you can see, there are now three potential problems
reported. Unlike errors which force Dolmen to abort the generation and
are always reported on the standard output, these problems are
recorded in a special reports file. By default, the reports file has
the name of the lexer description with an extra .reports extension;
this can be controlled on the command line with the -r/--reports
option. Inspecting the file shows it reports three warnings:
File "mypackage/JsonLexer.jl", line 20, characters 22-26:
Warning: The lexer entry main cannot recognize all possible input sequences.
Here are examples of input sequences which will result in an empty token error:
- 't' 'r' 'u' '\u0000'
- 't' 'r' '\u0000'
- 't' '\u0000'
- 'n' 'u' 'l' '\u0000'
- 'n' 'u' '\u0000'
- 'n' '\u0000'
- 'f' 'a' 'l' 's' '\u0000'
- 'f' 'a' 'l' '\u0000'
- 'f' 'a' '\u0000'
- 'f' '\u0000'
...
You may want to add '_' or 'orelse' catch-all clauses and provide a better error report.
File "mypackage/JsonLexer.jl", line 39, characters 24-30:
Warning: The lexer entry string cannot recognize all possible input sequences.
Here are examples of input sequences which will result in an empty token error:
- '\u0000'
You may want to add '_' or 'orelse' catch-all clauses and provide a better error report.
File "mypackage/JsonLexer.jl", line 50, characters 22-36:
Warning: The lexer entry escapeSequence cannot recognize all possible input sequences.
Here are examples of input sequences which will result in an empty token error:
- 'u' '\u0000'
- 'u' '0' '\u0000'
- 'u' '0' '0' '\u0000'
- 'u' '0' '0' '0' '\u0000'
- '\u0000'
You may want to add '_' or 'orelse' catch-all clauses and provide a better error report.These warnings are three instances of the same potential issue, one for each of our entries. The message explains that the entry "cannot recognize all possible input sequences" and goes on to give a few examples of unrecognized input strings.
This warning may come as a surprise: after all, a lexer is usually supposed to recognize some kind of language, and therefore should often reject at least some input sequences. As we have experienced already, an "Empty token" lexical error is raised by the generated lexer when an entry faces input which does not match any of the entry’s clauses. The actual idea behind this warning is to avoid occurrences of this lexical error, by encouraging programmers to account for invalid or unexpected input in their lexer descriptions, and raising exceptions with more specialized messages. Indeed, the "Empty token" message is really generic and rather unhelpful in most situations; in essence, it tells you the input cannot be recognized but does not tell you what is wrong, or what could be expected at this point in the stream.
Let us illustrate how our lexer can be improved can looking at the
escapeSequence rule:
private { char } rule escapeSequence =
| 'b' { return '\b'; }
| 't' { return '\t'; }
| 'n' { return '\n'; }
| 'f' { return '\f'; }
| 'r' { return '\r'; }
| '"' { return '"'; }
| '\'' { return '\''; }
| '\\' { return '\\'; }
| '/' { return '/'; }
| 'u' (hexDigit<4> as code)
{ return ((char)(Integer.parseInt(code, 16))); }The warning report for this rule lists the following as possible input sequences which would result in an empty token error:
- 'u' '\u0000'
- 'u' '0' '\u0000'
- 'u' '0' '0' '\u0000'
- 'u' '0' '0' '0' '\u0000'
- '\u0000'Indeed, the strings "u\000", "u0\000" and so on cannot be matched
by the escapeSequence rule. This is not an exhaustive list, of
course. In fact, when Dolmen internally compiles a lexer entry into a
deterministic finite automaton, it will look for different ways to
"get stuck" in the automaton, which correspond to input which would
not be recognized. When a way of traversing the automaton and getting
stuck is found, a corresponding canonical example is produced, by
taking the adequate string with the smallest characters. For instance,
the sequence "u0\000" stems for all input strings which start with a
u, followed by some hexadecimal digit (of which 0 is the
smallest), and then by any character other than a hexadecimal digit
(of which the null character \000 is the smallest). Similarly, the
null character in the sequence "\000" is the smallest possible
character which cannot start a valid escape sequence. This is why
the null character frequently appears in these report messages.
In essence, these examples of problematic input sequences remind us
that our escapeSequence rule will fail to match:
-
Unicode escape sequences which do not contain four hexadecimal digits;
-
input which starts with a character that is neither
u, nor any of the valid escape characters (b,t,n…).
Both instances reveal distinct syntactic problems and call for separate specific error messages. To that end, let us add two extra clauses to our entry:
private { char } rule escapeSequence =
...
| 'u' { throw error("Invalid Unicode escape sequence: \\uxxxx expected"); }
| _ as c { throw error("Invalid escape character: " + c + ". Valid ones are " +
"\\\\, \\/, \\\', \\\", \\n, \\t, \\b, \\f, \\r.");
}The first clause handles any invalid Unicode escaping sequence by
matching a single u character—recall that by the longest-match
disambiguation rule, this clause will not be used if u happens to be
followed by four hexadecimal digits. The second clause uses the
special wildcard regular expression _, which matches any single
character, to handle the case of all invalid escape characters. The
error() method used in
the semantic actions here is a method exported
by Dolmen’s base class for lexical analyzers and which simply
returns a LexicalError exception with the given message and associated
to the current lexer location. You can learn more about semantic actions
here.
|
Note that this second clause must appear after the other clauses: it matches exactly one character of the input stream, but so does the other clause for ’u'`and also the other clauses handling the various valid escape characters. When the input matches more than one clause and the longest-match rule does not apply, the clause appearing first will be applied. In this case, we want to make sure the wildcard clause is only used as a fall-back for invalid sequences, so we insert it last. If we had put the two extra clauses above the other way around, Dolmen
would actually warn you that the |
Now, if we recompile our lexer and look at the reports, we are
disappointed to see that there still is a warning about
escapeSequence being incomplete, albeit this time only a single
input example is reported in the diagnostic:
File "mypackage/JsonLexer.jl", line 50, characters 22-36:
Warning: The lexer entry escapeSequence cannot recognize all possible input sequences.
Here are examples of input sequences which will result in an empty token error:
- 'EOF'
You may want to add '_' or 'orelse' catch-all clauses and provide a better error report.The problematic input sequence is simply EOF, which is Dolmen’s way
of writing the special "end-of-input" character (not to be confused
with eof, which is the Dolmen keyword for the regular expression
that exactly matches this special character). Indeed, for reasons
which are detailed in a section dedicated to
wildcards in this manual, the _ regular expression in a clause
will match any character except EOF. Similarly, the character-set
complement construct [^…] will not match EOF either (which means
that _ and [^] are completely equivalent). In short, this stems
from the fact that the special end-of-input character behaves
differently from regular characters in regular expressions, and
usually calls for different error diagnostics in a lexical analyzer
anyways. In our case, we can fix our escapeSequence rule for good
by adding yet another clause, this time simply dealing with the case
when the input ends right at the beginning of the escape sequence:
private { char } rule escapeSequence =
...
| 'u' { throw error("Invalid Unicode escape sequence: \\uxxxx expected"); }
| _ as c { throw error("Invalid escape character: " + c + ". Valid ones are " +
"\\\\, \\/, \\\', \\\", \\n, \\t, \\b, \\f, \\r.");
}
| eof { throw error("Unterminated escape sequence"); }With these three fall-back clauses, our rule is finally warning-free, and we can test their effect by trying to tokenize a few various invalid sentences:
java -classpath bin:Dolmen_1.0.0.jar mypackage.Tokenizer
> "Some good escape:\nlike this" "And not so \good escape"
STRING(Some good escape:
like this)
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Invalid escape character: g. Valid ones are \\, \/, \', \", \n, \t, \b, \f, \r. (stdin, at line 1, column 45)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:651)
at mypackage.JsonLexer.escapeSequence(JsonLexer.java:163)
...
> "Nice Unicode\u0020sequence" "and a bad \u3 one"
STRING(Nice Unicode sequence)
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Invalid Unicode escape sequence: \uxxxx expected (stdin, at line 1, column 42)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:651)
at mypackage.JsonLexer.escapeSequence(JsonLexer.java:159)
...
> "Aborted escape sequence\
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Unterminated escape sequence (stdin, at line 1, column 26)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:651)
at mypackage.JsonLexer.escapeSequence(JsonLexer.java:168)
...We can fix the similar warnings pertaining to the main and string
entries in a similar fashion, by adding clauses to deal with unhandled
characters:
public { Token } rule main =
...
| _ as c { throw error("Unexpected character: " + c); }
| eof { return EOF; }
private { String } rule string =
...
| _ as c { throw error(
String.format("Forbidden character in string U+%04x", (short)c)); (1)
}
| eof { throw error("Unterminated string literal"); }| 1 | In the string entry, we know invalid characters are all control
characters which are usually non-printable, and therefore we
display them using their Unicode standard notation. |
The lexer description now compiles without any warnings! Altogether, we added six simple clauses, around 10 lines of code, and we statically made sure the generated lexical analyzer will never throw a generic empty token error, always using our custom messages.
We have improved error reporting in our lexical analyzer by making the rules explicitly deal with invalid input and customize error messages, but we did not go overboard doing so. Here are a few ways to further enhance error reporting:
-
in
escapeSequence, we could have made a special case forUxxxxto suggest the user should use lowercaseuinstead; -
similarly, in
mainwe could have parsed identifiers made of letters and suggested either one of the actual JSON keywords (true,falseornull) based for instance on which one was the closest for the Levenshtein distance, or to suggest to enclose the identifier into double-quote delimiters (as it is a common mistake to omit the delimiters in JSON object keys, and many JSON parsers actually accept such invalid input).
There is a compromise to be made between the amount of code and maintenance that can be devoted to error handling on one side, and the actual core functionality of the lexer on the other side. In some contexts, it is certainly desirable to put a lot of effort into instrumenting the lexer in that fashion. In other contexts, such as when writing an analyzer which will for instance be part of a validation tool, that is often run in batch as part of continuous integration, or as part of back-ends which must have a high throughput and do not interact with users directly, then it is perfectly desirable to have the simplest possible lexer description, with only the core functionality in place.
Debugging locations
Reporting nice helpful messages when encountering ill-formed input is very valuable, but reporting them at the correct place is equally important! The various lexical errors we encountered in our earlier tests were always located at some position in the input, displayed in terms of a line and a column number:
org.stekikun.dolmen.codegen.LexBuffer$LexicalError: Invalid Unicode escape sequence: \uxxxx expected (stdin, at line 1, column 42)
at org.stekikun.dolmen.codegen.LexBuffer.error(LexBuffer.java:651)
...This is true for both the generic token errors raised by
Dolmen-generated code and the custom lexical errors we raise ourselves
in the semantic actions. Yet, for the latter, we never bothered to
explicitly specify an input location when throwing the exception; in
fact, the error() library function
inherited from LexBuffer that
we used to build the lexical exception did choose a position
automatically. To make sure these positions are relevant, one needs to
get a good grasp of the principles behind them. Not only are positions
used to report lexical errors, they are also typically used in parsers
built on top of the lexers, to report syntactic errors, decorate
parsed abstract syntax trees with source locations, etc. It is quite
hard to debug these mechanisms thoroughly and make sure they always
use correct locations, and errors later reported at invalid or random
locations in a compiler back-end can cause quite a few headaches.
Fortunately, we will see how Dolmen can help assist in achieving and
maintaining relevant locations throughout the lexical analysis.
For a start, it is about time we confront our lexical analyzer to a
fully fledged JSON file instead of one-line sentences. We could adapt
our Tokenizer class to read from a file and display all tokens, but
this time we are interested in displaying the input locations
associated to the tokens as well. The two methods
getLexemeStart() and
getLexemeEnd() inherited from the base
LexBuffer class can be used in semantic actions to
retrieve the positions of the part of the input which matched the
current clause: getLexemeStart() will return the position of the
first character of the match, while getLexemeEnd() will return the
position of the first character which follows the match.
The positions themselves
consist of the following information:
-
the name of the input where the position is to be interpreted, it stems from the name given when creating the lexer instance;
-
the absolute offset of the position, in characters from the start of the input;
-
the line number where the position occurs in the input;
-
the absolute offset of the start of that line in the input, from which, together with the offset of the position, the column number of the position can be retrieved.
Part of the position information, namely the name and absolute offset,
are managed automatically by the generated lexer, whereas the other
part is the responsibility of the developer writing the lexer
description. The
org.stekikun.dolmen.debug
package contains utilities to help one debug lexical analyzers; using
the Tokenizer class from this package, it is very easy to tokenize an
input file as follows:
package mypackage;
import java.io.File;
import java.io.IOException;
import org.stekikun.dolmen.codegen.LexBuffer;
import org.stekikun.dolmen.debug.Tokenizer;
import mypackage.Token;
import mypackage.JsonLexer;
public class TokenizerLocs {
public static void main(String args[]) throws IOException {
String input = args[0];
String output = args[0] + ".tokens";
Tokenizer.file(
Tokenizer.LexerInterface.of(JsonLexer::new,(1)
JsonLexer::main,(2)
Token.EOF),(3)
new File(input), new File(output),(4)
true);(5)
}
}| 1 | A way to construct a lexical analyzer |
| 2 | The lexer’s entry point to use during the tokenization |
| 3 | The token at which tokenization should stop |
| 4 | The input and output files to use |
| 5 | Whether token locations should be output |
The
Tokenizer.file
method used in this example requires an interface describing what
lexical analyzer to use, and how to use it, and will tokenize any
given input file, printing the results to the specified output
file. Suppose we have a simple JSON file, adequately called
simple.json, in a resources folder of our working directory:
./
├─ Dolmen_1.0.0.jar
├─ bin/
│ └─ ...
├─ resources/
│ └─ simple.json
└─ mypackage/
└─ ...
{ "persons": ["Joe", "Bob", null],
"open": true,
"loc": [-12.45, 3.40e1],
"text": "sdfk\"j"
}Calling this tokenizer on simple.son will produce the following
results:
$ java -classpath bin:Dolmen_1.0.0.jar mypackage.TokenizerLocs resources/simple.json
$ cat resources/simple.json.tokens
LBRACE (simple.json[1,0+0]..simple.json[1,0+1])
STRING(persons) (simple.json[1,0+10]..simple.json[1,0+11])
COLON (simple.json[1,0+11]..simple.json[1,0+12])
LBRACKET (simple.json[1,0+13]..simple.json[1,0+14])
STRING(Joe) (simple.json[1,0+18]..simple.json[1,0+19])
COMMA (simple.json[1,0+19]..simple.json[1,0+20])
STRING(Bob) (simple.json[1,0+25]..simple.json[1,0+26])
COMMA (simple.json[1,0+26]..simple.json[1,0+27])
NULL (simple.json[1,0+28]..simple.json[1,0+32])
RBRACKET (simple.json[1,0+32]..simple.json[1,0+33])
COMMA (simple.json[1,0+33]..simple.json[1,0+34])
STRING(open) (simple.json[1,0+42]..simple.json[1,0+43])
COLON (simple.json[1,0+43]..simple.json[1,0+44])
...
RBRACE (simple.json[1,0+98]..simple.json[1,0+99])Each token is followed by its (start..end) locations, where each
position is given in the format name[l,b+c] where name is the
name of the input, l the line number, b the absolute offset of the
beginning of that line, and c the 0-based column number of the
position in that line. It is immediately clear that JsonLexer does
not update line numbers correctly since every token is supposedly at
line 1, whereas the column offsets keep growing. For instance, the
last closing curly brace is showed as being on the 99-th column of the
first line, wheras it is actually the first character of the 5-th
line; that being said, it is indeed the 99-th character of the whole
file, which shows the absolute position for this token was actually
right.
The issue here is that lexers generated by Dolmen keep track of a
current line number, but do not update it automatically. In order to
fix our locations, we must thus tell the underlying lexing buffer when
a new line starts. This is typically done from a semantic action by
calling the helper method newline(),
available from the base LexBuffer class. Calling newline() will
simply increment the current line count, and tell the engine that a
new line starts at the end of the current match. This is the reason
why, earlier in this tutorial, we took care of writing two separate
clauses for regular whitespace and for linebreaks, making sure we
matched linebreaks separately, and one at a time:
public { Token } rule main =
| ws { continue main; }
| nl { continue main; }
...It is easy now to fix the semantic action for our linebreak clause,
by calling newline() before continuing with the main rule:
public { Token } rule main =
| ws { continue main; }
| nl { newline(); continue main; }
...There is no other clause in JsonLexer.jl which successfully matches
a line break, but if JSON allowed multi-line string literals for
instance, we would need a similar clause with a call to newline() in
the string entry. After this fix, the locations of our tokens look
better:
$ java -classpath bin:Dolmen_1.0.0.jar mypackage.TokenizerLocs resources/simple.json
$ cat resources/simple.json.tokens
LBRACE (simple.json[1,0+0]..simple.json[1,0+1])
STRING(persons) (simple.json[1,0+10]..simple.json[1,0+11])
COLON (simple.json[1,0+11]..simple.json[1,0+12])
LBRACKET (simple.json[1,0+13]..simple.json[1,0+14])
STRING(Joe) (simple.json[1,0+18]..simple.json[1,0+19])
COMMA (simple.json[1,0+19]..simple.json[1,0+20])
STRING(Bob) (simple.json[1,0+25]..simple.json[1,0+26])
COMMA (simple.json[1,0+26]..simple.json[1,0+27])
NULL (simple.json[1,0+28]..simple.json[1,0+32])
RBRACKET (simple.json[1,0+32]..simple.json[1,0+33])
COMMA (simple.json[1,0+33]..simple.json[1,0+34])
STRING(open) (simple.json[2,35+7]..simple.json[2,35+8])
COLON (simple.json[2,35+8]..simple.json[2,35+9])
...
RBRACE (simple.json[5,98+0]..simple.json[5,98+1])|
One may wonder why calling
|
Looking closer at the locations returned for simple.json, it seems
that even though the line numbers now seem accurate, the actual
positions for some of the tokens look very suspicious; for instance,
the token STRING(open) for the "open" literal on line 2 only spans
one character according to the locations. We could look up the
actual positions in detail manually, but Dolmen’s
TokenVisualizer class offers a
more convenient way to check the token’s positions against the actual
input. Its usage is very similar to Tokenizer but instead of simply
displaying the tokens' information, it will generate a standalone HTML
page showing the tokens superimposed onto the original input:
package mypackage;
import java.io.File;
import java.io.IOException;
import org.stekikun.dolmen.codegen.LexBuffer;
import org.stekikun.dolmen.debug.TokenVisualizer;
import mypackage.Token;
import mypackage.JsonLexer;
public class Visualizer {
public static void main(String args[]) throws IOException {
String input = args[0];
String output = args[0] + ".html";
TokenVisualizer.file(
TokenVisualizer.LexerInterface.of(JsonLexer::new,(1)
JsonLexer::main,(2)
Token::getClass,(3)
Token.EOF),(4)
input, output);(5)
}
}| 1 | A way to construct a lexical analyzer |
| 2 | The lexer’s entry point to use during the tokenization |
| 3 | A way to split tokens into different categories |
| 4 | The token at which tokenization should stop |
| 5 | The input and output files to use |
In addition to the simpler Tokenizer, TokenVisualizer requires a
function to partition the tokens into several categories; tokens in
the same category will be highlighted with the same colour. Here we
simply use Token::getClass to sort the tokens by their actual type.
|
When using a token class generated from a Dolmen parser, an
enumeration |
Compiling our Visualizer class and running it on simple.json will
produce a
simple.json.html file
in the resources folder which looks like this:

The various tokens are conveniently displayed on top of the JSON input. Opening the file in a browser, we can hover the mouse over the various tokens to show the actual corresponding token and its recorded position:
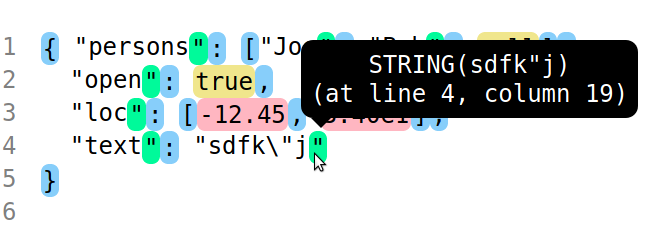
In this instance, we can see the contents of the token itself are
correct, in the sense that it is the string literal STRING(sdfk"j),
but its position is reduced to the closing double-quote, as is the
case for every string literal in the page. Tokens other than string
literals seem alright. To understand the issue with string literals,
remember that the lexeme start and end positions are updated each
time a clause is applied. Now, consider how the lexer will analyze
the first literal appearing in the file, "persons":
-
When the
main()rule is entered after the first two characters have been consumed already, both start and end positions point to the first available character, namely".
-
The clause of
main()which matches this input is:| '"' { buffer.setLength(0); String s = string(buffer); return STRING(s); }When entering this semantic action, the start and end positions reflect the fact that only one character has been matched:

-
The semantic action perform a nested call to another entry, namely
string(…). The rule will match all the contents of the literal via this clause:| [^'\000'-'\037' '"' '\\']+ { buf.append(getLexeme()); continue string; }When entering this clause, the positions reflect the part of the input which was matched:

Executing the action will append the match to the
buffer, and reenter recursively in thestringrule. -
As the
stringrule is reentered, the input will finally match the closing delimiter via this clause:| '"' { return buf.toString(); }and will thus return the contents of the buffer, namely
persons, back to the semantic action ofmain()that was entered earlier. The positions at this point reflect that the last match was the closing double-quote character:
-
Back in
main()'s semantic action, the tokenSTRING(persons)is built and returned, but the positions are still those associated with the last match. This explains why the string literal tokens ended up positioned at the corresponding closing".
In order to fix this, it is sufficient to simply save the current
start position after having matched the opening ", and restore
it after the nested call to the string rule has been completed.
That way, the situation in the lexer when the STRING(..) token
is returned is as follows:

This tampering with positions is the main downside to using nested
entries in a lexer description. It must be noted though that only
nested calls returning a token require this: there is no issue with
the nested call to escapeSequence or with the various continue
main and continue string — which incidentally is the reason why
Dolmen does not automatically save positions on the stack in nested
calls. Moreover, the saving and restoring of a position can be
performed in an elegant fashion by simply wrapping the nested call
with the
saveStart
method exported by LexBuffer:
string| '"' { buffer.setLength(0);
String s = saveStart(() -> string(buffer));
return STRING(s);
}After having amended our lexer description as above, recompiled
everything, and executed Visualizer again, the produced
simple.json.html
file now seems good all around:

|
It may seem that |
Afterword
We have now completed our lexical analyzer for JSON! In this tutorial, we have come a long way in terms of understanding the various features of a Dolmen lexer, how to best use them, and also how to overcome the potential obstacles that frequently arise. Here is our final lexer description:
import mypackage.Token;
import static mypackage.Token.*;
{
private final StringBuilder buffer = new StringBuilder();
}
ws = ['\t' ' ']+;
nl = ('\n' | '\r' | "\r\n");
digit = ['0'-'9'];
nzdigit = digit # '0';
int = '-'? ('0' | nzdigit digit*);
frac = '.' digit+;
e = ('e' | 'E') ('+' | '-')?;
exp = e digit+;
number = int frac? exp?;
hexDigit = digit | ['a'-'f' 'A'-'F'];
public { Token } rule main =
| ws { continue main; }
| nl { newline(); continue main; }
| '{' { return LBRACE; }
| '}' { return RBRACE; }
| '[' { return LBRACKET; }
| ']' { return RBRACKET; }
| ':' { return COLON; }
| ',' { return COMMA; }
| "true" { return TRUE; }
| "false" { return FALSE; }
| "null" { return NULL; }
| number { return NUMBER(Double.parseDouble(getLexeme())); }
| '"' { buffer.setLength(0);
String s = saveStart(() -> string(buffer));
return STRING(s);
}
| _ as c { throw error("Unexpected character: " + c); }
| eof { return EOF; }
private { String } rule string{StringBuilder buf} =
| '"' { return buf.toString(); }
| '\\' { char c = escapeSequence();
buf.append(c);
continue string;
}
| [^'\000'-'\037' '"' '\\']+
{ buf.append(getLexeme());
continue string;
}
| _ as c { throw error(
String.format("Forbidden character in string literal: U+%04x", (short)c));
}
| eof { throw error("Unterminated string literal"); }
private { char } rule escapeSequence =
| 'b' { return '\b'; }
| 't' { return '\t'; }
| 'n' { return '\n'; }
| 'f' { return '\f'; }
| 'r' { return '\r'; }
| '"' { return '"'; }
| '\'' { return '\''; }
| '\\' { return '\\'; }
| '/' { return '/'; }
| 'u' (hexDigit<4> as code)
{ return ((char)(Integer.parseInt(code, 16))); }
| 'u' { throw error("Invalid Unicode escape sequence: \\uxxxx expected"); }
| _ as c { throw error("Invalid escape character: " + c + ". Valid ones are " +
"\\\\, \\/, \\\', \\\", \\n, \\t, \\b, \\f, \\r.");
}
| eof { throw error("Unterminated escape sequence"); }
{ }It is 73 lines long, for a corresponding generated lexical analyzer of
just above 1000 lines. It strictly conforms to the lexical conventions
described in the JSON standard and handles all lexical
errors explicitly. Looking back at the complete lexer description, it
should be noted that there was nothing particularly difficult in the
lexer we wrote: we took things step-by-step in a slow fashion, went
astray at times for didactic purposes, detailed many aspects of
working with Dolmen lexers, but the resulting lexer is short, arguably
easy to read and understand, and performs as fast as a manually
crafted lexical analyzer (see comparison with
Gson below).
Whether you need lexical analysis for parsing a programming language
or for character streams' pre-processing, have fun with Dolmen!
The main design principles for Dolmen emphasize a lightweight and
flexible approach, as well as the robustness and reviewability of the
generated code. Performance is not strictly an objective per se, but
it is always interesting to see how the generated lexer will behave in
comparison to other existing solutions.
We test our JSON lexer using a
large JSON file of
over 189Mb (and over 20 million tokens). The file is analyzed a couple
times to give a chance to the JVM to "heat up"; the average time required
for tokenizing the file is then computed over 50 additional analyses.
Tokenizing in this context consists in calling the lexer’s main entry
repeatedly, and throwing the returned token away, until the end-of-input
is reached. The average time taken by our Dolmen lexer to process the
whole file is 4050ms, which amounts to a lexing rate of 45.76Mb/s.
We performed the exact same tests using Google’s Gson library, as well as with lexers we wrote with ANTLR and JFlex. The results are summarized in the figure below:
As you can see, the lexers generated by ANTLR and JFlex are slower than Dolmen’s, which in turn is a fraction slower than Gson’s, by less then a percent. Gson itself is not necessarily an industrial strength JSON parser — there exists such heavy duty parsers which can process hundreds of megabytes per second — but it is a mature library with a carefully hand-written JSON parser of around 1600 lines. That we are able to perform in a comparable fashion using a lexer generated from a short description is quite satisfactory.
Lexer Entries
The main building blocks of a Dolmen lexical analyzer are the lexer entries. Dolmen will generate a single Java method per entry in the resulting generated lexical analyzer. The syntax of a lexer entry is as follows:
An entry has a visibility (public or private), a return type, a name and optional parameters: all of these will propagate directly to the Java method generated from the entry. The remainder of the entry is a sequence of clauses which associate a regular expression to some arbitrary Java semantic action:
Instead of a regular expression, a clause can be introduced
with the special orelse keyword, whose meaning is explained
in a dedicated section below.
|
In essence, Dolmen lexers let you conveniently program methods which consume an input sequence of characters, recognize some input patterns described by regular expressions, and take on different actions depending on what patterns have been matched. Whether you use these actions to tokenize the input stream, to transform the input stream by extracting, decoding, encoding or filtering parts of it, to count occurrences of certain patterns or anything else, is completely irrelevant to Dolmen. Dolmen’s job is to take the high-level lexer description and turn it into an efficient analyzer by taking care of important details such as:
-
managing input loading and buffering;
-
compiling an entry’s clauses into efficient code which matches input and select the adequate semantic action;
-
keeping track of matched input positions, as well as those fragments corresponding to patterns captured via the
… as cconstruct; -
assisting users by statically detecting and reporting common mistakes in lexer descriptions, such as useless clauses, etc.
When more than one clause in the entry matches the current input, the
default disambiguation rule is to pick the clause which yields the
longest match. This behaviour can be changed for a given entry by
using the shortest keyword prior to the clauses: in this case,
priority is given to the clause yielding the shortest match. In any
case, when several clauses yield matches with the same length, the
clause which appears first in the lexer description will be selected.
The shortest-match rule is seldom used, at least for tokenizing purposes. It can prove useful when writing text stream processors, in particular when reading input from a network staream or from standard input, as entries which use the shortest-match rule never need to "look ahead" in the input stream and backtrack before selecting the correct clause, unlike regular longest-match entries.
Regular Expressions
In this section, we describe the Dolmen syntax for regular expressions. Regular expressions appear as part of clauses in lexer entries, but auxiliary regular expressions can also be defined before the lexer entries:
The identifier on the left-hand side in a regular expression definition is the name which can be used to denote that regular expression in subsequent definitions as well as in clauses. The various regular expression constructs are summarized in this table, we detail each of them in the following.
- Literals
-
The most basic form of regular expression are the character and string literals. A character literal such as
'a'or'\040'is a regular expression which simply matches the given character. Similarly, a string literal such as"foo"or"\r\n"is a regular expression which matches the given string. The exact syntax for character and string literals is detailed in the the lexical conventions.// Some literal regular expressions space = ' '; pub = "public";Additionally, there are two "special" literals
_andeof, respectively called wildcard and end-of-input.eofis a meta-character which represents the fact that the end of the input stream has been reached; in particular it does not really match a given character, but simply succeeds when the input stream has been exhausted. On the other hand, the wildcard_will match any single character from the input, and thus in particular is mutually exclusive witheof. These special literals are discussed further below. - Character classes
-
A character class is a way of denoting a regular expression which must only match a character in a subset of the whole character set. It is introduced by square brackets
[…]and can contain any non-empty sequence of:-
single character literals, such as
'a','0'; -
character ranges, such as
'a'-'z','0'-'9', denoting all the characters which belong to the specified range (inclusive on both ends); -
names of already defined regular expressions whose value corresponds to a character class (or can be reduced to a character class, such as a single character literal or the wildcard
_).
The meaning of a character class can also be completely inverted if it starts with a
^character, in which case it matches any character which does not belong to the specified set.// Some character classes whitespace = ['\t' space '\f']; alpha = ['a'-'z' 'A'-'Z']; nonctrl = [^'\000'-'\037'];The grammar for character classes is recalled in the syntax reference.
-
- Character class difference
-
The difference operator
r # slets one define a regular expression by taking the set of characters which match the given classrbut do not match the classs. The regular expressions used as operands for#must reduce to character classes or a lexical error will be reported by Dolmen.// Some character class differences digit = ['0'-'9']; nzdigit = digit # '0'; lowercase = alpha # ['a'-'z']; ctrl = _ # nonctrl; - Repetitions
-
Dolmen supports the following traditional postfix repetition operators:
-
r?matches zero or one occurrence of the regular expressionr; -
r+matches one or more occurrences of the regular expressionr; -
r*matches any number of occurrences of the regular expressionr, including zero.
Besides these basic operators, it is also possible to specify any finite number of repetitions using the following syntax where
nandmstand for literal decimal natural integers:-
r<n>matches exactlynoccurrences of the regular expressionr; -
r<n,m>matches anything betweennandm(inclusive) occurrences of the regular expressionr.
Note that
r<n>is just syntactic shortcut forr<n,n>, and thatr?is completely equivalent tor<0,1>. There is no way to specify an "infinite" upper bound, sor+andr*cannot be obtained with an instance ofr<n,m>. This is not a limitation in practice, since something like any number of repetitions larger or equal to 3 can be obtained by a combination such asr<3>r*.// Using repetition operators decimal = digit+; hexcode = [digit 'a'-'f' 'A'-'F']<4>; word = ['_' alpha]+; blanks = whitespace*; -
- Concatenation
-
The concatenation of two regular expressions
r sis a regular expression which first matchesrand thens. Concatenation is right-associative, and has strictly lower precedence than every operator we have seen so far. In particular, a string literal regular expression such as"foo"is just syntactic sugar for the concatenation'f''o''o'of its character literals. Similarly, a repetitionr<4>is just another, shorter, way of writingr r r r.// Using concatenation float = decimal ('.' decimal)?; string = '"' [^ ctrl '"']* '"'; r1 = 'a''b'+; // ab......b r2 = ('a''b')+; // abab...abNote how parentheses can be used to disambiguate or regroup regular expressions when natural precedence rules would not yield the intended result.
- Choice
-
The choice operator
r | smatches anything that either regular expressionrorsmatches. The choice operator is right-associative, and has strictly lower precedence than every operator we have seen so far, including concatenation. In particular, the regular expressionr?is equivalent tor | "".// Using the choice operator ident = alpha (alpha | digit | '_')*; newline = '\r' | '\n' | "\r\n"; r3 = 'a'|'b''c'; // a or bc r4 = ('a'|'b')'c'; // ac or bc - Capturing groups
-
The capture operator
r as cmatches exactly like the regular expressionrbut when successful, it also saves the part of the input stream which it matched. The matched contents are then made available in the semantic action of the corresponding clause as a local variable with namec. Captures are very convenient when the semantic action would otherwise need to extract some interesting part of the matched input, potentially at the cost of rescanning some of it.The type of a capture variable depends on the captured regular expression, and on the overall clause’s expression it appears in. It can be either
String,char,Optional<String>orOptional<Character>. TheOptionalwrappers are introduced when the overall regular expression can succeed without the captured regular expression having matched at all, such as in(r as c)?or(r1 as c) | r2. Other than that, a capture variable is normally of typeString, unless it captures a regular expression which can only statically match a single character (e.g. a character literal, a character class, a wildcard or an alternation of any of those), in which case its type is that of a Java character.The rationale behind the fact that the type of capture variables adapts to the regular expression is twofold:
-
Using a simpler type such as
charin comparison toStringenhances efficiency since no heap-allocation is required to capture a single character. Moreover, captured groups are always assigned before entering a clause’s semantic action, even if it is never going to be used in the semantic action. -
Wrapping optional captured groups with
java.util.Optionalgoes against raw efficiency instead, but for the very good reason of making sure that semantic actions always use captured variables in a way that is consistent with the associated clause. In particular, usingnullor default values instead would make it very easy for a developer to break a semantic action’s intended behaviour by only slightly changing the associated regular expression. With our approach, such a breaking change will normally result in a type-checking error in the compiler.
Dolmen does not enforce that a capture variable appears only once in a clause’s regular expression. This allows for instance patterns such as
(r1 as c) | (r2 as c)whereccan then be handled in a uniform fashion in the semantic action. The type of a capture variable which appears more than once in a regular expression is simply the "simplest" type which can accomodate all occurrences of the variable. For instance, the capture variable can only have typecharif all its occurrences can have typechar, and so on.Examples of captures in action// North-American style phone number, capturing groups phone = (digit<3> as area) '-' (digit<3> as office) '-' (digit<4> as num); // Markdown-style header, capturing the title header = '#'+ blanks ([^ '\r' '\n']+ as title) newline; // GCC #line directive, capturing filename and line number linedir = "#line" blanks (digit+ as line) blanks (string as filename); // Java Unicode escape sequence, capturing the code unit value unicode = '\\' 'u'+ (hexcode as code);Even when a capture variable is bound only once in a regular expression, it is possible that it is part of a repeated expression, for instance
(r as c)<2>, and can therefore be matched several times during a single overall match. In such a case, the variable will be bound to the contents that correspond to the last match. Similarly, if the same capture variable appears nested in a captured group, such as in(r0 (r1 as c) r2) as c, only the outermost occurrence can ever find its way into the semantic action. The innermost captures are actually optimized away very early by Dolmen, and do not even contribute to the choice of the type associated to the variablec.Finally, there may be cases where there is not a unique way of matching the input stream with some regular expression, and that the different ways would yield different captured contents. For instance, consider matching the string
aaaaawith the regular expression('a'<2,3> as i) ('a'<2,3> as j): there are two correct ways in whichiandjcould be assigned. In such a case, which one is produced by the Dolmen-generated lexical analyzer is left unspecified. -
The following table summarizes the different regular expression constructs in order of decreasing precedence, i.e. operators appearing first bind tighter than those appearing later down the table.
| Name | Syntax | Meaning | Associative |
|---|---|---|---|
Difference |
|
Matches the characters in |
No |
Option |
|
Matches like |
No |
Kleene star |
|
Matches any number of repetitions of |
No |
Kleene plus |
|
Matches one or more number of repetitions of |
No |
Repetition |
|
Matches exactly |
No |
Bounded repetition |
|
Matches between |
No |
Concatenation |
|
Matches |
Right-associative |
Choice |
|
Matches either |
Right-associative |
Capture |
|
Matches like |
Left-associative |
Semantic Actions
When a matching clause has been chosen by the lexing engine and the corresponding prefix of the input consumed, the associated semantic action is executed. The semantic action can be almost arbitrary Java code, but must respect a few principles.
-
The semantic action must be such that all paths are guaranteed to adequately exit the control-flow, which means that every execution path must end with either of the following:
-
a
returnstatement, compatible with the declared return type of the enclosing entry; -
the throwing of an uncaught exception (preferably a
LexicalErrorexception); -
a Java
continue lblstatement to restart the current lexer entrylblwithout actually calling the Java method implementing the entry (cf. tail-recursion); this works because Dolmen always generates the code of a lexer entry in a loop with a labeled statement whose label is exactly the name of the entry.
When this principle is not respected, the generated code may contain errors or warnings, and the behaviour of the generated lexical analyzer is not predictable.
-
-
The generated lexer is a subclass of the
LexBufferclass from the Dolmen runtime, and as such has access to a number of fields and methods inherited fromLexBuffer. Some of these fields and methods are provided primarily for use by user code in semantic actions, whereas others deal with the internal functionality of the lexing engine and should not be called or tampered with in semantic actions. The reader may wonder why these fields and methods which are reserved for internal use are declared asprotected; they cannot be madeprivateinLexBufferbecause they must be accessed from the code of the subclass generated by Dolmen itself.In order to document which protected members are intended for user code and which are off limits, the
DolmenInternalannotation has been introduced and is used to annotate every member which is declared asprotectedbut should not be accessed from user code (i.e. either from semantic actions or from the prelude and postlude). As a refinement, a field can be annotated with@DolmenInternal(read = true)in which case access to the field from user code is tolerated as long as the value is not modified. In this context, "modifying" a field encompasses both modifying the field itself, and in the case the field is a reference object, modifying the actual value of the referred object without changing the reference itself. For instance, the following declaration is possible:@DolmenInternal(read = true) protected final Set<Integer> numbers;It signifies that
numberscan be read from user code—the field itself cannot be modified as it is final anyway—but only methods which do not change the contents ofnumbersshould be allowed. As the Java language lacks a proper notion ofconst-ness, it cannot be expressed in method signatures whether they observationally change their receiver’s state or not so one must rely on documentation and common sense in practice.When internal members are used in semantic actions, the lexical analyzer may behave unexpectedly as this can break some of the internal invariants it relies on. Even if things seem to work fine, such code can be broken by a future Dolmen update.
We conclude this section on semantic actions with an exhaustive
presentation of the fields and methods from
LexBuffer which are available for use
in semantic actions. One can always refer to the Javadoc associated
to these members, either via the HTML pages
or using your IDE when accessing the Dolmen runtime.
- Input position
-
The following members available in semantic actions relate to the management of the input position.

String filename-
This field contains the name of the current input being analyzed by the lexing engine. Despite the field’s name, this name need not be an actual filename, it is only used in positions and error reporting.
It is not final as it may be changed for instance when handling a GCC-like#linedirective. -
Position startLoc -
This field contains the starting position of the current lexeme.
It can be modified before returning from a semantic action, e.g. for adjusting token locations when the lexical analyzer is used by a parser. -
Position curLoc -
This field contains the ending position of the current lexeme, i.e. the position of the first character that follows the lexeme.
It can be modified before returning from a semantic action, e.g. for adjusting token locations when the lexical analyzer is used by a parser. 
void newline()-
Modifies the internal line and column counter to account for the consumption of a line terminator. This needs to be called in semantic actions accordingly if one wants to keep correct track of lines and columns.
-
<T> T saveStart(Supplier<T> s) -
This convenience method calls the given supplier
s, returning the same value ass, but saving the current value ofstartLocbefore the call and restoring it afterwards. This is used when nested rules are used to parse a token and the token location needs to be adjusted. -
<T> T savePosition(Supplier<T> s, Position start) -
This convenience method calls the given supplier
s, returning the same value ass, but setting the value ofstartLoctostartafterwards. This is used when nested rules are used to parse a token and the token location needs to be adjusted. -
void saveStart(Runnable r) -
This convenience method calls the given runnable
r, saving the current value ofstartLocbefore the call and restoring it afterwards. This is used when nested rules are used to parse a token and the token location needs to be adjusted. -
void savePosition(Runnable r, Position start) -
This convenience method calls the given runnable
rand sets the value ofstartLoctostartafterwards. This is used when nested rules are used to parse a token and the token location needs to be adjusted. 
void disablePositions()-
This method can be used to disable position tracking in the lexer. It must be called first before the lexer is used, and should not be called again afterwards. Once position tracking is disabled, the
startLocandcurLocfields are set to an arbitrary invalid value and are not updated by the lexical analyzer anymore. -
boolean hasPositions() -
Returns whether position tracking is enabled in the current analyzer or not. Position tracking is enabled by default and can be disabled with the
disablePositions()method.
- Lexeme
-
The following members available in semantic actions relate to the retrieval of the last matched lexeme. They all refer to the part of the input which was last matched by a lexer clause; in the case where there have been calls to a nested rule, these methods will return information relevant to the last matched clause, and not to the lexeme which was matched by the clause of the current semantic action.
-
String getLexeme() -
Returns the last matched lexeme.
-
Position getLexemeStart() -
Returns the starting position of the last matched lexeme.
-
Position getLexemeEnd() -
Returns the end position of the last matched lexeme. By convention, this is the position of the first character that follows the lexeme.
-
int getLexemeLength() -
Returns the length of the last matched lexeme.
-
char getLexemeChar(int idx) -
Returns the character at index
idxin the last matched lexeme. The index is 0-based, and must be between 0 (inclusive) andgetLexemeLength()(exclusive). -
CharSequence getLexemeChars() -
Returns the contents of the last matched lexeme as a character sequence. The character sequence refers to the current internal state of the lexing engine and becomes unspecified after nested rule calls, even if it was retrieved before any nested call.
-
void appendLexeme(StringBuilder buf) -
Appends the contents of the last matched lexeme to the given buffer
buf.
- Input management
-
The following members available in semantic actions relate to the management of the input stream during a lexical analysis. The lexing engine supports switching input streams in the middle of an analysis, and can manage an input stack to let users implement inclusion directives like GCC’s
#includeor TeX’s\input.-
void changeInput(String fn, Reader reader) -
This closes the current input stream and switches to the new input specified by
readerand whose display name will befn. -
void pushInput(String fn, Reader reader) -
This pushes the current input stream on the input stack and start consuming the given
readerinstead. The stacked input stream can be resumed withpopInput(). -
boolean hasMoreInput() -
This returns whether the current stream is the last one remaining in the input stack. In other words, only when this method returns
truecanpopInput()be used. -
void popInput() -
This closes the current stream and resumes the last one which was pushed to the stack. Whether the stack is empty or not can be checked beforehand with
hasMoreInput.
- Error management
-
The following members available in semantic actions relate to error management during a lexical analysis.
-
LexicalError error(String msg) -
Returns a
LexicalErrorexception with the given message string and reported at the current lexer position. This is the preferred way of reporting lexical errors in semantic actions. Note that unlike the other methods here,erroris not final: it can be overriden so that one can for instance customize the way the error message is built and presented. In particular it could be internationalized if need be. -
char peekNextChar() -
Returns the character which directly follows the last matched lexeme in the input stream, or 0xFFFF if end-of-input has been reached. This can be used to produce better error messages, or in some cases where a semantic action needs to look ahead at the stream without consuming it to decide what should be done.
-
int peekNextChars(char[] buf) -
Copies the characters which directly follow the last matched lexeme in the input stream to
buf, and returns the number of characters actually copied. This can be used to produce better error messages, or in some cases where a semantic action needs to look ahead at the stream without consuming it to decide what should be done.
Understanding eof, _ and orelse
In this section, we discuss the meaning of the special regular
expressions eof and _, which can sometimes be confusing, as well
as the special orelse keyword which can be used to introduce a
"catch-everything-else" clause in a lexer entry.
- End-of-input
-
As explained above,
eofis a special regular expression literal which matches when the input stream has been exhausted. It actually represents the single meta-character\uFFFF, which is used internally to represent the end-of-input and is not a valid escaping sequence in character or string literals. Even ifeofis internally encoded as a character, it does not behave as a character:-
matching
eofdoes not consume any character from the input stream, it simply checks that the end of the input stream has indeed been reached; therefore it always matches an empty input string, whereas regular characters always match an input of size 1; -
because it does not consume anything,
eofhas some rather exotic properties when it comes to regular expressions; for instance,eofandeof+are completely equivalent; -
eofis not considered as a regular expression which reduces to a character class; hence it is not possible to useeofin a character set difference operation.. # .., or inside a character class[.. eof ..]; -
finally, even though
eofstands for the end of the input stream, any regular expression which matches the empty string can still match aftereof, e.g.eof "",eof ("" as c)or eveneof ("foo"?)will all successfully match the empty string"".
All in all, writing complex regular expressions using
eofshould be really uncommon. As a rule of thumb,eofis usually best used all by itself in a clause, as the end-of-input normally calls for some ad hoc action, in particular in terms of error reporting. -
- Wildcard
-
The wildcard
_is a regular expression which can match any valid character. It is actually equivalent to the character class['\u0000' - '\uFFFE'], and in particular excludes the end-of-input meta-character. Therefore,_will behave in an expected way, consuming exactly one character of the input stream, much like.in many common regular expression engines.What sometimes causes confusion is that
_is not sufficient when trying to write a default clause to catch any unexpected character for instance:| _ as c { throw error("Unexpected character: " + c); }This will catch any actual unexpected character but will still leave
eofunhandled—and if so, this will be reported by Dolmen as a warning for a potentially incomplete lexer entry. It is possible to match(_ | eof) as cor(_ as c) | eofof course, but whereascin the clause above had typechar,cin the latter examples would be anOptional<Character>which means the semantic action will not handle both cases in a uniform manner anyway. It is usually simpler to just have another clause dedicated toeof.Note that for the same reason that
_only matches actual non end-of-input characters, the character class complement operation[^…]only contains characters in the 0x0000-0xFFFE range. In other words, the complement[^ cset ]of some character set is actually equivalent to_ # [cset]. - Clause
orelse -
The keyword
orelsecan be used in place of a regular expression to introduce a special form of clause:| orelse { ... }The meaning of the
orelsepattern depends on the context in which it is used, namely of the other clauses declared before in the same lexer entry. Its purpose is to match the longest possible prefix of input which could not possibly match any of the other clauses above.More precisely, suppose
orelseis preceded by n clauses with respective regular expressionsr1, …rn; the regular expression thatorelsewill denote is computed as follows:-
For each
ri, compute the character setCiof the characters which can start a match ofri. This character set can easily be computed by induction on the regular expression; for instance, it is the first character of the string for a string literal, the union of the first characters ofsandtfor a choice expressions | t, and so on. -
Compute the union
Cof all the character setsCi, i.e. the set of all the characters which can start a match of any of theri. -
Then,
orelsewill represent the regular expression[^C]+, i.e. it will match any non-empty number of characters which cannot start any of theri.
An
orelseclause is useful when one is only interested in recognizing certain patterns, but can pass over the rest of the input without having to interpret it. Consider for instance a lexer entrymlcommentwhich is entered when starting a (possibly multi-line) comment/* … */and which must match until the end of the comment:An entry for multi-line commentsprivate { void } rule mlcomment = | "*/" { return; } | newline { newline(); continue mlcomment; } | eof { throw error("Unterminated comment"); } | ...where
newlineis defined as('\r' | '\n' | "\r\n"). As it is, the entry recognizes the closing comment delimiter and also handles line breaks and end-of-input gracefully. It still needs to be able to pass everything else that the comment can contain. One correct way to do that is to use a wildcard to catch everything else:... | _ { continue mlcomment; }In particular this works because by the longest-match rule, it will not match a
*character if it happens to be followed by a/. Unfortunately, reentering the rule at every character is somewhat inefficient in comparison to matching largest parts of the comment at once; indeed, every time a rule is entered or reentered, the generated lexical analyzer performs some minor bookkeeping regarding the current lexeme’s positions. To pass as much of the comment’s contents as we possibly can in one go, we can use an ad-hoc regular expression like the following:... | [^'*' '\r' '\n']+ { continue mlcomment; }The issue with this is twofold:
-
On one hand, it is fragile as it relies on correctly listing all characters which are of interest to the other clauses in the rule. Should we forget one of them, the Kleene
+operator and the longest-match rule will conspire to make sure our entry does not work as intended. Also, this must be maintained when adding new patterns to the rule. -
On the other hand, it still does not cover the case of
*characters which are not followed by a/. One could of course fix the regular expression like this:... | ([^'*' '\r' '\n']+ | '*'+[^'/' '*'])+ { continue mlcomment; }but this would definitely make the first issue even more pregnant (Hint: incidentally, this regular expression is still not good enough!).
Reliability and reviewability are design principles in Dolmen, and the
orelseclause was brought up precisely to bring an elegant solution for such a case. Usingorelsehere will be equivalent to[^'*' '\r' '\n']+but in a much less error-prone way:private { void } rule mlcomment = | "*/" { return; } | newline { newline(); continue mlcomment; } | eof { throw error("Unterminated comment"); } | '*' { continue mlcomment; } | orelse { continue mlcomment; }Of course, lonely
*characters still need to be singled out but this is reasonably simple. One can even switch the last two clauses around and use a wildcard:private { void } rule mlcomment = ... | orelse { continue mlcomment; } | _ { continue mlcomment; }Writing the entry this way will make maintenance really straightforward. For instance, suppose we want to start allowing nested
/* … */comments, this can be achieved by keeping track of the current comment "depth" in a local field and add a clause to handle opening delimiters:private { void } rule mlcomment = | "*/" { if (--depth == 0) return; continue mlcomment; } | "/*" { ++depth; continue mlcomment; } | newline { newline(); continue mlcomment; } | eof { throw error("Unterminated comment"); } | orelse { continue mlcomment; } | _ { continue mlcomment; }The benefit of using
orelseand a wildcard instead of complex hand-crafted expressions is immediately apparent, as this is all that we have to do to handle nested comments in our entry.orelsewill now take care of not consuming/characters, whereas the wildcard will deal with/characters that are not followed by a*.Note that as in the example above, the
orelseclause need not be the last one in the entry, it will simply depend on the clauses defined above. It is even syntactically possible to have more than oneorelseclause in an entry, although all such extra clauses will be shadowed by the first one by construction. -
Lexer Options
The lexical analyzer generator accepts some options which can be specified right at the top of a lexer description, with the following syntax:
[key1 = "value1"]
[key2 = "value2"]
...A configuration option given as a key-value pair where the key identifies the option being set, and the value is a string literal. Unlike string literals in regular expressions, option values can be multi-line string literals.
In the following, we list the different configuration options available in lexer descriptions and document their effect.
- class_annnotations
-
The
class_annotationsoption lets one specify arbitrary annotations that will be added on the class generated by the lexical analyzer. Indeed, a lexer description will result in the generation of a single public class extending the base lexing buffer class from the Dolmen runtime.This can be useful in particular to add particular instances of
@SuppressWarnings(…)annotations. Dolmen tries very hard to generate code without warnings—not counting warnings from the semantic actions of course, at least for a reasonable default configuration of the Java compiler. When working in a project with stronger requirements, generated classes may have warnings and theclass_annotationsoption can be used to explicitly ignore these warnings. For instance, to suppress warnings on missing Java documentation in the generated lexer, one can use:[class_annotations = "@SuppressWarnings(\"javadoc\")"]When referencing an annotation from another package, make sure it is fully qualified or add the corresponding import to the imports section of the lexer description, so that the annotation can be resolved in the generated Java compilation unit. For instance, when working in a project which uses the Eclipse JDT null analysis, one may need something like this:
[class_annotations = "@org.eclipse.jdt.annotation.NonNullByDefault"]as Dolmen is implemented with the full null analysis enabled and uses a non-null type default policy.
Command Line Interface
The Dolmen runtime is an executable Java archive which can be used as a command-line tool to generate a lexical analyzer from a lexer description. Another way of using Dolmen is via the companion Eclipse plug-in; nonetheless, the command line is useful in a variety of scenarios like building scripts, Makefile, continuous integration, etc.
The command line interface can be invoked as follows:
$ java -jar Dolmen_1.0.0.jar -l ..options.. sourcewhere source is the name of the source lexer description. The -l
option instructs Dolmen that the source is a lexer description and that
a lexical analyzer should be generated. The -l flag can be omitted
if the source file has the .jl extension. The other available
command line options are detailed in the following table.
| Name | Type | Default | Description |
|---|---|---|---|
|
Flag |
No |
Displays help about command line usage. |
|
Flag |
No |
Quiet mode: suppresses all output except for error report. |
|
Flag |
No |
Generates a lexical analyzer from the source file. |
|
String |
Working directory |
Output directory for the generated class. |
|
String |
Name of the source file |
Name of the generated class. |
|
String |
Required |
Name of the package for the generated class. |
|
String |
Name of the source file + |
File where potential problems should be reported. |
|
Flag |
No |
Disable colors in output. |
String options must follow the option name directly, e.g. -o mydir
--class Foo instructs Dolmen to generate the class Foo.java in the
mydir directory. Flag values in their short form can be grouped
together. For instance, -lq instructs Dolmen to generate a lexical
analyzer in quiet mode. Note that the --package/-p option is
required: the generated class will be declared in the given package,
and Dolmen does not support generating classes in the default
package.
The following command will generate a lexical analyzer in
src/foo/bar/MyLexer.java, in the package foo.bar.
Only errors will be reported on the standard output, other
reports will be in MyLexer.jl.reports.
$ java -jar Dolmen_1.0.0.jar -q -p foo.bar -o src/foo/bar MyLexer.jlThe following command will generate a lexical analyzer in
src/foo/bar/MyLexer.java, in the package foo.bar.
The -l flag is required as Dolmen cannot recognize the
extension of the source description.
Dolmen will output information on the different phases
of the lexical analyzer generation, including any errors.
Other problem reports will be written to lexer.reports.
$ java -jar Dolmen_1.0.0.jar -l -p foo.bar --reports lexer.reports src/foo/bar/MyLexer.lexerAdvanced Concepts
In the remaining sections, we take a quick tour of some advanced principles lexical analysis with Dolmen. These concepts have all already been introduced, in more or less depth, in the tutorial.
Nested Rules
When trying to tokenize an input stream containing some sentences in a programming language or some data in an non-binary exchange format, it it usually apparent that the same characters may take on very different meanings depending on the context in which they appear.
For instance, special symbols like + or ; which represent
operators or separators in one part of the input, need not be
interpreted in any special manner when they appear inside a string
literal, or inside some comment. Similarly, a keyword loses its
special status should it belong to some comment or literal. Many
languages even embed some other language in their syntax, in one form
or another; consider for instance GCC’s preprocessor directives which
are added on top of the C language, or more evidently the presence of
Java actions inside Dolmen lexer descriptions. Even simple traits such
as literals supporting a variety of escape sequences, or interpreted
documentation comments such as Javadoc or Doxygen, can be thought of
as "mini"-languages inside the main programming language.
The GCC preprocessor does not need to parse the C declarations between the preprocessor directives, no more than Dolmen actually needs to parse the semantic actions in Java, but both need to be able to care for the lexical conventions of the embedded language. Trying to write a lexical analyzer which can handle preprocessing directives, complex literals, structured comments and embedded snippets in some external language, without being able to effectively separate the different concerns raised by these different contexts, amounts to writing a single very complex entry rule whose clauses are able to recognize everything. Imagine clauses like these:
public { Token } rule main =
...
| '"' (string_literal as s) '"' { return Token.STRING(decode(s)); }
| '{' (java_action as a) '}' { return Token.ACTION(a); }
| '#' (pp_directive as d) '\n' { handle(d); continue main; }
| "/*" ml_comments "*/" { continue main; }
...Let us first ignore how complex these regular expressions ought to be, and just discuss each clause’s purpose:
-
The
string_literalclause recognizes a literal string’s contents, with possible escape sequences for control characters or Unicode code points. The escape sequences are unescaped by thedecodefunction in the semantic action before returning the token. One could store the literal without decoding the escape sequences, but this will need to be done at some point in time when the program needs to interpret or expose the literal’s value. -
The
java_actionclause recognizes a Dolmen-style Java action delimited by curly braces. It turns out it is impossible to write such a regular expression because{and}can appear nested inside the Java actions and thus the language to recognize is not regular, but we could make do by picking more discriminating delimiters such as{%and%}, the way JFlex does. Thejava_actionstill needs to correctly analyze the Java lexicon, as it needs to be able to ignore occurrences of%}inside Java string literals or Java comments. -
The
pp_directiveclause recognizes some sort of preprocessing directive. As is often the case with preprocessing, it may not be part of a separate first phase, but may be applied on-the-fly during the lexical analysis. Here, we suppose the directive is directly handled by some methodhandlein the semantic action, before handing control back to the lexer. This method may register a new macro, push some new file on the input stack, etc. It must decode and validate the raw directive which has been recognized. -
The
ml_commentsclause recognizes C-style multi-line comments. It may contain structured comments aimed at tools like Javadoc or Doxygen, and in this case the clause simply skips the comment. Not trying to interpret the contents of the comment, we can surely leave this task to external tools which will be applied independently on the source code. But what if we are precisely writing a documentation tool like these? In that case, not only do we need to handle and decode the contents of the structured comments, but we also need to recognize the remainder of the language with enough precision, so that it is possible for instance to ignore occurrences of/*appearing in a string literal. Even if we can avoid interpreting the comments, lexing a multi-line comments in one go means that line and column numbers cannot be properly updated (cf. newline()), except by scanning for line terminators in the semantic action. Finally, if we ever wanted to support nested comments, such as(* .. *)comments in OCaml, then sadly it would not be possible to write a suitableml_commentsregular expression as nested comments are not a regular language.
These examples basically sum up the main reasons why we want some form of contextual rules in lexer generation:
-
writing and maintaining correct complex regular expressions like
java_actionorstring_literalis precisely what lexer generators are supposed to help one avoid; -
even when recognized successfully, the internal structure of these lexemes must still be decoded eventually, and that task will somewhat duplicate the work that the generated lexer did when recognizing the expression; not only is it inefficient, it also duplicates the actual logic of the internal structure;
-
when the contents of a string literal or a Java action happen to be lexically invalid (e.g. because of an invalid escape sequence), the lexical error will be returned at the very beginning of the clause, which is not very helpful; the only way to provide a better error message is to write other clauses matching invalid cases and throw custom error messages.
Lexer generators like ANTLR, JavaCC or JFlex allow contextualization by introducing a notion of state and letting users associate different lexing rules to different states, as well as switching states in semantic actions.
| Unlike JavaCC and JFlex which call them "lexical states", ANTLR actually calls these states "modes", which is arguably a better way of characterizing them, as the lexical analyzer’s state is not reduced to the current mode. Instead the analyzer’s state comprises the whole stack of modes which have been entered and are yet to be returned from. |
Dolmen does not follow a state-based approach but a function-based one, inspired by OCaml’s lexer generator ocamllex. In this approach, lexing rules are grouped in different lexer entries which each correspond to a different function in the generated lexer. Each entry can correspond to a different lexing context, and switching from one context to another is done by calling the adequate entry. A lexer description could contain different public entries which are designed to be called independently from an external class; it can also feature a main entry and other private entries which are only designed to be called from other entries' semantic actions. We call such rules which are accessed via calls nested in other rules' semantic actions nested rules.
We now demonstrate the use of nested rules on the examples of string literals and nested comments.
Let us use nested rules to recognize string literals like "abc"
supporting simple escape sequences \n, \\ and \". We start
in the main rule by matching the opening delimiter:
...
| '"' { StringBuilder buf = new StringBuilder();
String s = string(buf); // Nested call
return Token.STRING(s);
}When the opening " is matched, a buffer for the literal’s contents
is allocated and passed to the nested rule string which will match
the literal and decode its contents into the buffer at the same time.
private { String } rule string(StringBuilder buf) =
| '"' { return buf.toString(); }
| '\\' 'n' { buf.append('\n'); continue string; }
| '\\' '"' { buf.append('"'); continue string; }
| '\\' '\\' { buf.append('\\'); continue string; }
| '\\' { throw error("Invalid escape sequence"); }
| eof { throw error("Unterminated string literal"); }
| orelse { appendLexeme(buf); continue string; }The nested rule returns the buffer’s contents when encountering a
closing ". When it reads a valid escape sequence, it appends the
encoded character to the buffer. When it reads an invalid escape
sequence or encounters the unexpected end-of-input, it throws an
adequate error. Other characters are just appended to the buffer as
they are.
The tutorial shows a more complete example of this on the JSON format, in particular using another nested rule dedicated to escape sequences.
Let us use nested rules to recognize nested multi-line /* .. */
comments. We will rely on a local field depth of type int to track
the current nesting level when analyzing the comments—this field must
have been declared in the prelude. We start in the main rule by
matching the opening delimiter:
...
| "/*" { depth = 0;
ml_comments(); // Nested call
continue main;
}When the opening /* is matched, the nesting depth is set to 0 and
the nested rule is called to start analyzing the comment’s contents.
private { void } rule ml_comments() =
| "*/" { if (depth == 0) return;
--depth; continue ml_comments;
}
| "/*" { ++depth; continue ml_comments; }
| newline { newline(); continue ml_comments; }
| eof { throw error("Unterminated comments"); }
| orelse { continue ml_comments; }
| _ { continue ml_comments; }The nested rule returns when encountering the closing */ while on
depth zero, and otherwise decrements the depth and continues running
the same rule. The depth is incremented when a nested /* is
encountered. The rule also takes care of tracking line breaks to
update the line and column numbers, and to throw an error should the
end-of-input be reached before the comments end.
There is yet another possible advantage of using separate dedicated entries for parts of a language, and it is to factorize the rules for similar patterns which can be found in different contexts. For instance, the escape sequences available in string literals may be completely identical to the escape sequences in character literals, and having a dedicated entry for escape sequences can help factorize the two in a single set of rules.
When using nested rules, one must be aware of the couple of subtleties. First, it is possible to write a recursive entry, or a group of mutually recursive entries, in which case the user should be aware of the possibility of stack overflow. This is discussed below. Second, the internal state of the lexing buffer is updated when performing nested calls, and a number of the inherited methods available during semantic actions do depend on this internal state. For instance the following clause may observe the internal state being overwritten by the nested call inside:
| r { Position start = getLexemeStart(); (1)
String lex = getLexeme(); (2)
nested_rule(); (3)
Position start2 = getLexemeStart(); (4)
String lex2 = getLexeme(); (5)
}| 1 | Retrieving the starting position of the lexeme matched by r. |
| 2 | Retrieving the string matched by r. |
| 3 | Performing some nested call, which overwrites the internal state of the lexer. |
| 4 | Retrieving the starting position of the last lexeme
matched in nested_rule. |
| 5 | Retrieving the contents of the last lexeme matched
in nested_rule. |
If you find this situation surprising, consider that preventing it
would require Dolmen to keep a stack of all relevant information
across nested calls, which would be costly for the frequent cases when
this information is not needed. When it indeed is needed, it is
straightforward to just retrieve it before performing nested calls, as
is the case in the example above for start and lex. The
next section precisely covers how to deal
with managing token positions across nested rules.
Managing Token Locations
Coming soon
Tail-Recursion
When using nested rules in a lexer description, one should be wary of nested calls being so deep that the lexical analysis could cause the Java program to excess its stack space, leading to a StackOverflowError being thrown. This is realistically only an issue with recursive calls, i.e. when some rule is called from its own semantic actions, either directly or indirectly through other rules.
For instance, consider a lexing rule main() with a clause for
skipping Python comments (assuming for the sake of conciseness that
the only line terminator is the line feed character):
public { Token } rule main() =
...
| '#' [^'\n']* '\n' { newline(); return main(); }
...This clause will consume the comment until (and including) the end of
the line, and continues analyzing the input stream with the same rule
by calling main() recursively. This recursive call to main() has
the peculiarity of being a
tail-call, i.e. that
this call is the very final action taken in this function. As such,
the call could be optimized so that the callee’s frame can reuse the
space of the caller’s frame, a process dubbed tail-call
optimization. Tail-call optimization is not limited to recursive
tail-calls, but it is an important feature of compilers for functional
languages where recursion is a key paradigm. Unfortunately, Java does
not have tail-call optimization in general, so code like the clause
above will use an amount of stack space that is proportional to the
largest number of consecutive comment lines # … in the source.
This can be arbitrary large, and it is not rare to find very long
comment blocks in real code.
The standard countermeasure to prevent a recursive function from
blowing up the stack in the absence of tail-call optimization is to
rewrite the recursion as a regular loop. It is particularly
straightforward when the function was tail-recursive in the first
place. Dolmen provides this possibility by generating the code
for every lexer entry inside a while loop labelled with
the name of the rule itself. Therefore, the code for the entry
main will follow this structure:
public Token main() {
main:
while (true) {
... // Consumes input, find matching clause
... // Executes corresponding semantic action
}
}This layout allows using Java’s continue statement to continue
executing the rule main without explicitly calling it recursively,
namely by rewriting our clause for Python comments as follows:
public { Token } rule main() =
...
| '#' [^'\n']* '\n' { newline(); continue main; }
...As the semantic action will simply jump back to the beginning of the
entry and start scanning again, this version of main uses a constant
amount of stack (barring issues in other clauses) and can accomodate
thousands of contiguous lines of comments.
The strategy of resorting to a continue statement has two
limitations.
-
If the rule which is reentered using
continuehas parameters, it is not possible to change these parameters withcontinuewhereas it would be possible with an explicit tail-call. For instance, consider a rule which recognizes nested{ .. }expressions—similarly to Dolmen’s own rule for lexing semantic actions in lexer descriptions—and is parameterized by the current nestingdepth, representing the number of}still to find:... // Somewhere in another rule | '{' { return action(1); } ... private { ... } rule action(int depth) = | '{' { return action(depth + 1); } | '}' { if (depth == 1) return ...; else return action(depth - 1); } | _ { continue action; }This snippet can use
continuein the last clause, when simply looking for more curly braces, but must usereturnin the first two clauses in order to update the depth level accordingly. A simple way to fix such a rule is to add an instance field to the lexer’s prelude and use it instead of passing a parameter toaction. Another possibility is to define a mutable container class for the rule’s parameters, in our case a simple integer, and pass such a container to the rule:{ // In the prelude private static class DepthLevel { int val = 1; } } ... ... // Somewhere in another rule | '{' { return action(new DepthLevel()); } ... public { ... } rule action(DepthLevel depth) = | '{' { depth.val++; continue action; } | '}' { if (depth.val == 1) return ...; depth.val--; continue action; } | _ { continue action; } -
The second limitation with
continueis that it can be used solely with direct recursion, and not in the case of several mutually recursive rules. This arguably rarely arises in practical cases. Consider two rules which recognize both{ … }and[ … ]blocks, delimited respectively by curly and square brackets. Suppose each kind of block can include the other kind of block, as long as things remain well-parenthesized. A natural description of these two rules could be:// Somewhere in main rule | '{' { return curlyBlock(); } | '[' { return squareBlock(); } ... private { ... } rule curlyBlock = | '}' { return; } | '[' { return squareBlock(); } | _ { continue curlyBlock; } private { ... } rule squareBlock = | ']' { return; } | '{' { return curlyBlock(); } | _ { continue squareBlock; }This is simple enough, but the stack will not survive input which contain long sequences like "[{[{[{[{[{[{[ …. ]}]}]}]}]}]}]}". The only way to force such rules to use constant stack space is to merge the mutually recursive rules together into a single lexer entry. This may be quite tedious in general depending on the rules' clauses, but in this case this is rather pedestrian as the clauses from the two rules do not really interfere. Nevertheless, we must take care of tracking whether the last opened block was a curly or squared one, and the overall number of all blocks that have been opened so far. For that reason we introduce a local container class to represent that state of the combined rule:
{ // In prelude private static Blocks { private Blocks(int depth, boolean inCurly) { this.depth = depth; this.inCurly = inCurly; } static Blocks newCurly() { return new Blocks(1, true); } static Blocks newSquare() { return new Blocks(1, false); } int depth; boolean inCurly; } } // Somewhere in main rule | '{' { return blocks(Blocks.newCurly()); } | '[' { return blocks(Blocks.newSquare()); } ... private { ... } rule blocks(Blocks st) = | '{' { if (!st.inCurly) { st.depth++; st.inCurly = true; } continue blocks; } | '}' { if (st.inCurly) { st.depth--; if (st.depth == 0) return; st.inCurly = false; } continue blocks; } | '[' { if (st.inCurly) { st.depth++; st.inCurly = false; } continue blocks; } | ']' { if (!st.inCurly) { st.depth--; if (st.depth == 0) return; st.inCurly = true; } continue blocks; } | _ { continue blocks; }Now, do not worry if this transformation does not look that "pedestrian". Arguably, one should only very rarely have a really good reason to use a lexical analyzer to parse something like this. It is possible nonetheless, and is worth showcasing for the sake of completeness. Also, as a matter of style, a class such as
Blocksin the example above should probably be implemented in a companion Java file and not in the lexer description’s prelude. The prelude should really only contain fields or local helper methods which access the state of the underlying lexing engine.
Dolmen Lexers: Syntax Reference
In this section we present the complete syntax reference for Dolmen lexer descriptions. We start with the lexical structure of Dolmen lexers before describing the actual grammar of the language.
Lexical conventions
The following lexical conventions explain how the raw characters in a Dolmen lexer description are split into the lexical elements that are then used as terminals of the grammar.
- White space
-
The five following characters are considered as white space: space
(0x20), horizontal tab(0x09), line feed(0x0A), form feed(0x0C)and carriage return(0x0D). The line feed and carriage return characters are called line terminators. White space does not produce lexical elements but can serve as separator between other lexical elements. - Comments
-
Comments follow the same rules as in the Java language. They can be either end-of-line comments
// …extending up to a line terminator, or traditional multi-line comments/* ... */. Comments cannot be nested, which means in particular that neither//nor/*are interpreted inside a traditional multi-line comment. As with white space, comments do not produce lexical elements but can serve as separators between other lexical elements. - Identifiers (
IDENT) -
Identifiers are formed by non empty-sequences of letters (a lowercase letter from
atoz, an uppercase letter fromAtoZ, or the underscore character_) and digits (from0to9), and must start with a letter. For instance,id,_FOOor_x32_yare valid identifiers. Some otherwise valid sequences of letters are reserved as keywords and cannot be used as identifiers. - Literal integers (
LNAT) -
A literal integer is either
0or any non-zero digit followed by a number of digits between0and9. Its value is interpreted as a decimal integer. Any such sequence of digits which produces a value that does not fit in a 32-bit signed integer results in a lexical error. - Character literals (
LCHAR) -
A character literal is expressed as a simple character or an escape sequence between single quotes
'…'. A simple character can be any character other than',\and line terminators. An escape sequence can be any of the following:-
an octal character code between
\000and\377, representing the character with the given octal ASCII code; -
an escape sequence amongst
\\,\',\",\r(0x0D),\n(0x0A),\b(0x08),\t(0x09) and\f(0x0C); -
a Unicode character code between
\u0000and\uFFFE, representing the corresponding UTF-16 code unit; just like in Java, there can be any positive number ofucharacters before the actual hexadecimal code.
For instance, possible character literals are
'g','$','\'','\047'or'\uuu0027'. The last three happen to all represent the same character.Note that the character
\uFFFFis not allowed as it is reserved to represent the end-of-input; it is not a valid Unicode character anyway. -
- String literals (
LSTRING,MLSTRING) -
A string literal is expressed as a sequence of simple characters and escape sequences between double quotes
"…". A simple character is any character other than"and\. An escape sequence is exactly as described for character literals.
Unlike in Java, line terminators may be allowed inside string literals, representing their own value. Nonetheless, single-line string literals and multi-line string literals will produce different lexical elements (resp.LSTRINGandMLSTRING) which can then be distinguished in the grammar. Indeed, multi-line string literals are only syntactically valid as option values, and their usage elsewhere will result in a syntax error during the parsing phase.
Characters and escape sequences in a string literal are
interpreted greedily in the order in which they appear, and
therefore a \ character will only be understood as the start of an
escape sequence if the number of other backslash \ that
contiguously precede it is even (which includes zero).Therefore, the string literal "\\u006E" is interpreted as an
escaped backslash followed by "u006E".
|
As in Java, Unicode code points outside the Basic Multilingual
Plane cannot be represented with a single character or escape
sequence; one must use two code points (a
surrogate
pair) instead. For instance, the Unicode code point U+1D11E,
which is the symbol for the musical G clef 𝄞, can be
obtained with two Unicode escape sequences \uD834\uDD1E.
|
- Java actions (
ACTION) -
Java actions are lexical elements which represent verbatim excerpts of Java code. They are used as part of the semantic actions associated to a lexer entry’s clauses, to express the Java return type and arguments of a lexer entry, and also for the top-level header and footer of the generated lexical analyzer.
A Java action is a block of well-delimited Java code between curly braces:{ …well-delimited Java code… }. A snippet of Java code is well-delimited if every character literal, string literal, instruction block, method, class or comment that it contains is correctly closed and balanced. This essentially ensures that Dolmen is able to correctly and safely identify the closing}which delimits the end of the Java action.
The following snippet:
{ // TODO Later }is not a valid Java action because the internal end-of-line comment
is not closed inside the action. In fact the closing } is understood
as being part of the Java snippet and thus part of the comment (as
revealed by the syntax highlighting). Adding
a line break makes this a valid Java action:
{ // TODO Later
}The following snippet:
{ System.out.printf("In action \"Foo\"); }is not a valid Java action because the internal String literal is not properly closed inside the action. Closing the literal makes this a valid Java action:
{ System.out.printf("In action \"Foo\""); }| Dolmen’s companion Eclipse plug-in offers editors with syntax highlighting, including relevant syntax highlighting inside Java actions. It is obvious in the examples above that decent Java-aware syntax highlighting goes a long way in helping one avoid silly typos and syntactic mistakes inside Java actions. |
|
Dolmen’s lexical conventions for white space, comments and
literals follow those used in the Java programming
language. In particular, Dolmen will follow the same rules
when encountering character or string literals inside and
outside Java actions. There is a subtle but important
difference between Dolmen and Java though:
unlike
Java, Dolmen does not unescape Unicode sequences in a
preliminary pass but during the main lexical translation
instead. Therefore, if one uses a Unicode escape code to
stand for a line terminator, a delimiter or a character in an
escape sequence, it is possible to write valid Java code that
is not a valid Java action, or the other way around. Consider for instance the Java literal "Hello\u0022: this
is a valid Java string because \u0022 is first replaced by
the double quote character ", but as far as Dolmen is
concerned this is an incomplete string literal whose first
six characters were Hello". Another example is "\u005C"
which is a valid Dolmen string representing the single
character \, and is understood by Java as being an
incomplete string literal whose first character is ". |
- Keywords
-
The following lower-case identifiers are reserved keywords of the language:
as,eof,import,orelse,private,public,rule,shortest,static. - Operators and punctuation
-
The following symbols serve as operators or punctuation symbols in Dolmen lexer descriptions:
=,|,[,],*,?,+,(,),^,-,#,.,<,>,,,;.
Any input sequence which does not match any of the categories above will result in a lexical error.
Grammar of Dolmen Lexers
We give the complete grammar for Dolmen lexer descriptions below. The
terminals of the grammar are the lexical elements described infra,
and keywords, punctuation and operator symbols are displayed in
boldface. The main symbol is Lexer and we use traditional
BNF syntax to
present the grammar’s rules, augmented with the usual repetition
operators ? (at most one), + (at least one) and * (any number
of repetitions).
Options, Imports and Auxiliary Definitions
Import := import (static)? Typename ;
Lexer Entries
Regular Expressions
Regular := | Regular as IDENT // as is left-associative | AltRegular AltRegular := | SeqRegular | AltRegular // choice | SeqRegular SeqRegular := | PostfixRegular SeqRegular // concatenation | PostfixRegular PostfixRegular := | DiffRegular * // zero, one or more occurrences | DiffRegular + // at least one occurrence | DiffRegular ? // at most one occurrence | DiffRegular < LNAT > // fixed # of occurrences | DiffRegular < LNAT , LNAT > // min. and max. # of occurrences | DiffRegular DiffRegular := | AtomicRegular # AtomicRegular // only with char classes | AtomicRegular AtomicRegular := | _ // all characters except eof | eof // end-of-input | LCHAR // a single character | LSTRING // an exact sequence of characters | IDENT // defined regular expression | CharClass // a character class | ( Regular )
CharClass := [ CharSet ] CharSet := | ^ CharSetPositive // complement character set | CharSetPositive CharSetPositive := | LCHAR // a single character | LCHAR - LCHAR // a range of characters (inclusive) | IDENT // defined character set | CharSetPositive CharSetPositive // union of character sets
Parsers
Coming soon
Dolmen Parsers: Syntax Reference
In this section we present the complete syntax reference for Dolmen parser descriptions. We start with the lexical structure of Dolmen parsers before describing the actual grammar of the language.
Lexical conventions
The following lexical conventions explain how the raw characters in a Dolmen parser description are split into the lexical elements that are then used as terminals of the grammar.
- White space
-
The five following characters are considered as white space: space
(0x20), horizontal tab(0x09), line feed(0x0A), form feed(0x0C)and carriage return(0x0D). The line feed and carriage return characters are called line terminators. White space does not produce lexical elements but can serve as separator between other lexical elements. - Comments
-
Comments follow the same rules as in the Java language. They can be either end-of-line comments
// …extending up to a line terminator, or traditional multi-line comments/* ... */. Comments cannot be nested, which means in particular that neither//nor/*are interpreted inside a traditional multi-line comment. As with white space, comments do not produce lexical elements but can serve as separators between other lexical elements. - Identifiers (
IDENT) -
Identifiers are formed by non empty-sequences of letters (a lowercase letter from
atoz, an uppercase letter fromAtoZ, or the underscore character_) and digits (from0to9), and must start with a letter. For instance,id,_FOOor_x32_yare valid identifiers. Some otherwise valid sequences of letters are reserved as keywords and cannot be used as identifiers. - String literals (
MLSTRING) -
A string literal is expressed as a sequence of simple characters and escape sequences between double quotes
"…". A simple character is any character other than"and\; in particular string literals can span multiple lines in a Dolmen parser description. An escape sequence can be any of the following:-
an octal character code between
\000and\377, representing the character with the given octal ASCII code; -
an escape sequence amongst
\\,\',\",\r(0x0D),\n(0x0A),\b(0x08),\t(0x09) and\f(0x0C); -
a Unicode character code between
\u0000and\uFFFF, representing the corresponding UTF-16 code unit; just like in Java, there can be any positive number ofucharacters before the actual hexadecimal code.
For instance, possible characters in a string literal are
g,$,\',\047or\uuu0027. The last three happen to all represent the same character. -
Characters and escape sequences in a string literal are
interpreted greedily in the order in which they appear, and
therefore a \ character will only be understood as the start of an
escape sequence if the number of other backslash \ that
contiguously precede it is even (which includes zero).Therefore, the string literal "\\u006E" is interpreted as an
escaped backslash followed by "u006E".
|
As in Java, Unicode code points outside the Basic Multilingual
Plane cannot be represented with a single character or escape
sequence; one must use two code points (a
surrogate
pair) instead. For instance, the Unicode code point U+1D11E,
which is the symbol for the musical G clef 𝄞, can be
obtained with two Unicode escape sequences \uD834\uDD1E.
|
- Java actions (
ACTION) -
Java actions are lexical elements which represent verbatim excerpts of Java code. They are used as part of the semantic actions associated to a parser rule’s productions, to express the Java return type of a rule or the Java type of the value associated to a token, and also for the top-level header and footer of the generated syntactic analyzer.
A Java action is a block of well-delimited Java code between curly braces:{ …well-delimited Java code… }. A snippet of Java code is well-delimited if every character literal, string literal, instruction block, method, class or comment that it contains is correctly closed and balanced. This essentially ensures that Dolmen is able to correctly and safely identify the closing}which delimits the end of the Java action.
Because Dolmen grammar rules can be parametric, Java actions are not necessarily copied verbatim in the generated parser: some generic parts of the Java action may undergo a substitution to account for the actual instantiation of a rule’s formal parameters. To that end, Java actions can contain placeholders of the form#keycalled holes, wherekeymust be any identifier starting with a lower-case letter. When instantiating grammar rules, these holes are filled by Dolmen with the Java types of the formal parameters whose names match the holes' keys. One limitation of this mechanism is that holes are not interpreted when they appear inside a Java comment, character literal or string literal. In other contexts, the#character can safely be interpreted as a hole marker since it is not a Java separator or operator symbol.
The following snippet:
{ // TODO Later }is not a valid Java action because the internal end-of-line comment
is not closed inside the action. In fact the closing } is understood
as being part of the Java snippet and thus part of the comment (as
revealed by the syntax highlighting). Adding
a line break makes this a valid Java action:
{ // TODO Later
}The following snippet:
{ System.out.printf("In action \"Foo\"); }is not a valid Java action because the internal String literal is not properly closed inside the action. Closing the literal makes this a valid Java action:
{ System.out.printf("In action \"Foo\""); }The following snippet:
{
// See A#foo()
List<#elt> l = new ArrayList<#elt>();
}is a valid Java action with holes referencing some formal
parameter elt. The #foo in the comment is not
interpreted as a hole.
| Dolmen’s companion Eclipse plug-in offers editors with syntax highlighting, including relevant syntax highlighting inside Java actions which also recognizes holes. It is obvious in the examples above that decent Java-aware syntax highlighting goes a long way in helping one avoid silly typos and syntactic mistakes inside Java actions. |
|
Dolmen’s lexical conventions for white space, comments and
literals follow those used in the Java programming
language. In particular, Dolmen will follow the same rules
when encountering character or string literals inside and
outside Java actions. There is a subtle but important
difference between Dolmen and Java though:
unlike
Java, Dolmen does not unescape Unicode sequences in a
preliminary pass but during the main lexical translation
instead. Therefore, if one uses a Unicode escape code to
stand for a line terminator, a delimiter or a character in an
escape sequence, it is possible to write valid Java code that
is not a valid Java action, or the other way around. Consider for instance the Java literal "Hello\u0022: this
is a valid Java string because \u0022 is first replaced by
the double quote character ", but as far as Dolmen is
concerned this is an incomplete string literal whose first
six characters were Hello". Another example is "\u005C"
which is a valid Dolmen string representing the single
character \, and is understood by Java as being an
incomplete string literal whose first character is ". |
- Java arguments (
ARGUMENTS) -
Java arguments are very similar to Java actions in that they are lexical elements which represent verbatim excerpts of Java code. They are used to declare a parser rule's arguments and to pass arguments to a non-terminal in a production.
Java arguments are formed by a block of well-delimited Java code between parentheses:( …well-delimited Java code… ). The snippet of Java code is well-delimited if every character literal, string literal, or parenthesized expression that it contains is correctly closed and balanced. This essentially ensures that Dolmen is able to correctly and safely identify the closing)which delimits the end of the Java arguments.
Like Java actions, Java arguments can contain holes in the form of identifiers introduced by a#character. Holes are only interpreted outside Java comments and literals. - Keywords
-
The following lower-case identifiers are reserved keywords of the language:
continue,import,private,public,rule,static,token. - Operators and punctuation
-
The following symbols serve as operators or punctuation symbols in Dolmen lexer descriptions:
=,|,[,],.,<,>,,,;.
Any input sequence which does not match any of the categories above will result in a lexical error.
Grammar of Dolmen Parsers
We give the complete grammar for Dolmen parser descriptions below. The
terminals of the grammar are the lexical elements described infra,
and keywords, punctuation and operator symbols are displayed in
boldface. The main symbol is Parser and we use traditional
BNF syntax to
present the grammar’s rules, augmented with the usual repetition
operators ? (at most one), + (at least one) and * (any number
of repetitions).
Options, Imports and Auxiliary Definitions
Import := import (static)? Typename ;
Grammar Rules and Productions
Rule := (public | private) ACTION // rule's return type rule IDENT // must start with lowercase letter (FormalParams)? // rule's optional formal parameters (ARGUMENTS)? // rule's optional arguments = Production+ ; FormalParams := < IDENT (, IDENT)* > // formals must start with lowercase letter Production := | Item*
Production Items and Actuals
Actual := ActualExpr (ARGUMENTS)? // optional arguments to the actual
ActualExpr := | IDENT // a terminal or ground non-terminal | IDENT < ActualExpr (, ActualExpr)* > // application of a parametric non-terminal